在AI領(lǐng)域,自O(shè)penAI推出ChatGPT以來,全球范圍內(nèi)的大模型競爭便如火如荼地展開。這場競爭不僅推動了技術(shù)的進(jìn)步,也引發(fā)了業(yè)界對于模型開源與閉源的深入思考。
近期,隨著Deeseek等開源大模型的涌現(xiàn),業(yè)界再次迎來了開源的高潮。許多開發(fā)者發(fā)現(xiàn),開源的大模型因為易于獲取和使用,受到了廣泛的歡迎。然而,在AI大模型的發(fā)展道路上,存在著兩種截然不同的策略。
一方面,以O(shè)penAI為代表的巨頭們,憑借著雄厚的資金實力,大量采購頂級GPU卡,通過堆算力來打造高性能AI。這種“大力出奇跡”的策略,雖然耗資巨大,但對于擁有充足資源的公司來說,無疑是一條行之有效的道路。

另一方面,像Deepseek這樣的公司,由于資金和資源有限,他們選擇了另一條道路——用最少的顯卡,實現(xiàn)最強的性能。這種“四兩撥千斤”的策略,不僅降低了成本,還取得了令人矚目的成果,一度讓華爾街的巨頭們潰不成軍。
然而,就在業(yè)界普遍認(rèn)為開源與低成本是未來的趨勢時,一款國產(chǎn)大模型——阿里通義千問大模型Qwen3(簡稱千問3)橫空出世,再次刷新了人們的認(rèn)知。這款模型不僅開源,而且在性能和成本控制上實現(xiàn)了驚人的突破。
千問3作為全球首個“混合推理模型”,將“快思考”與“慢思考”兩種模式完美融合,根據(jù)不同需求進(jìn)行靈活處理。這種創(chuàng)新的設(shè)計,使得千問3在處理簡單問題時能夠迅速響應(yīng),而在面對復(fù)雜問題時,則能夠進(jìn)行深度思考,從而提供更為準(zhǔn)確的答案。
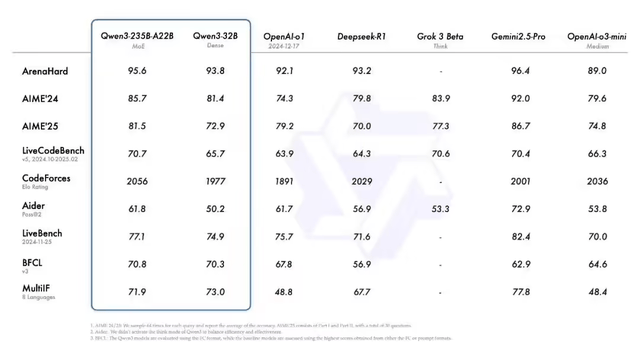
更令人興奮的是,千問3在性能和成本控制上的表現(xiàn)堪稱驚艷。它只需要DeepSeek-R1三分之一的參數(shù)規(guī)模,就能夠?qū)崿F(xiàn)超越的性能。這意味著,部署千問3的成本將大大降低,同時顯存占用量和部署難度也將得到顯著優(yōu)化。
具體來說,使用4張H20顯卡,就可以部署全功能的千問3模型。這一優(yōu)勢,無疑將大大降低AI技術(shù)的門檻,使得更多的企業(yè)和開發(fā)者能夠輕松上手。

自Deepseek推出以來,國內(nèi)就掀起了一股國產(chǎn)GPU替代的熱潮。許多企業(yè)發(fā)現(xiàn),即使不使用英偉達(dá)的頂級顯卡,也能夠部署出強大的AI模型。這一發(fā)現(xiàn),不僅打破了OpenAI的神話,也打破了英偉達(dá)的算力泡沫。
而千問3的推出,無疑將進(jìn)一步加速國產(chǎn)GPU替代的進(jìn)程。由于千問3在性能和成本控制上的卓越表現(xiàn),使得國產(chǎn)GPU在AI領(lǐng)域的應(yīng)用前景更加廣闊。這對于國內(nèi)GPU廠商來說,無疑是一個巨大的機遇。

隨著千問3等國產(chǎn)大模型的崛起,我們有理由相信,在未來的AI領(lǐng)域,國產(chǎn)技術(shù)和產(chǎn)品將占據(jù)越來越重要的地位。