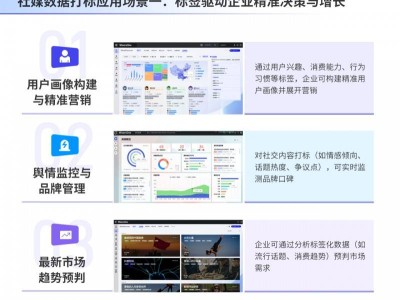
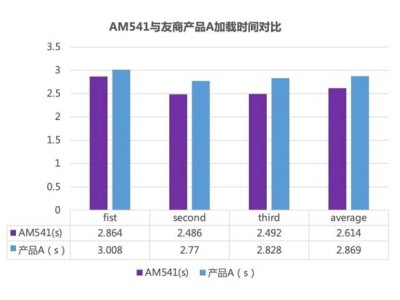
近期,meta公司推出了全新的WebSSL系列視覺模型,這一系列模型的參數(shù)規(guī)模橫跨3億至70億,專注于無語言監(jiān)督的視覺自監(jiān)督學習(SSL)領(lǐng)域。該系列模型的推出,標志著meta在探索視覺表征學習新路徑上的重大進展,為未來的多模態(tài)任務應用提供了更多可能性。
在人工智能領(lǐng)域,多模態(tài)任務的表現(xiàn)一直備受關(guān)注,OpenAI的CLIP模型便是其中的佼佼者,尤其在視覺問答(VQA)和文檔理解等任務中表現(xiàn)突出。然而,CLIP模型的訓練依賴于大規(guī)模且復雜的語言數(shù)據(jù)集,這在一定程度上限制了其廣泛應用。為了突破這一局限,meta利用自家的metaCLIP數(shù)據(jù)集(包含20億張圖像)進行訓練,完全摒棄了語言監(jiān)督,旨在純粹通過視覺數(shù)據(jù)來提升模型性能。
實驗結(jié)果表明,隨著模型參數(shù)規(guī)模的增加,WebSSL在VQA任務中的表現(xiàn)呈現(xiàn)出顯著提升。特別是在OCR和圖表解讀任務中,WebSSL的表現(xiàn)甚至超越了CLIP模型。當通過高分辨率(518px)進行微調(diào)時,WebSSL在文檔理解任務中的表現(xiàn)也取得了大幅提升,進一步縮小了與一些高分辨率模型的差距。
值得注意的是,盡管WebSSL模型是在無語言監(jiān)督的條件下進行訓練的,但它們?nèi)匀徽宫F(xiàn)出與一些預訓練語言模型(如LLaMA-3)的良好對齊性。這一發(fā)現(xiàn)表明,大規(guī)模視覺模型能夠在沒有顯式語言監(jiān)督的情況下,隱式地學習到與文本語義相關(guān)的特征。這一發(fā)現(xiàn)為視覺與語言之間的關(guān)系提供了新的視角和思考。
meta的WebSSL系列模型的推出,不僅在傳統(tǒng)基準測試中取得了優(yōu)異表現(xiàn),更為未來無語言監(jiān)督學習的研究開辟了新的方向。這一系列模型的成功,標志著meta在推動人工智能領(lǐng)域創(chuàng)新方面邁出了重要一步。