英偉達近期在人工智能領域取得了新突破,推出了一款名為Describe Anything 3B(簡稱DAM-3B)的先進AI模型,專門用于解決圖像和視頻中特定區域的詳細描述難題。
傳統的視覺-語言模型在描述整體圖像時表現尚可,但一旦涉及到對圖像中某個特定區域的細致描述,尤其是視頻中的動態場景,其能力就顯得捉襟見肘。英偉達此次推出的DAM-3B模型,正是為了解決這一技術瓶頸。
DAM-3B模型允許用戶通過點選、邊界框、涂鴉或掩碼等方式,精準指定想要描述的目標區域,隨后模型會生成與上下文高度契合的精確描述文本。英偉達還推出了DAM-3B-Video版本,專門用于處理動態視頻內容。
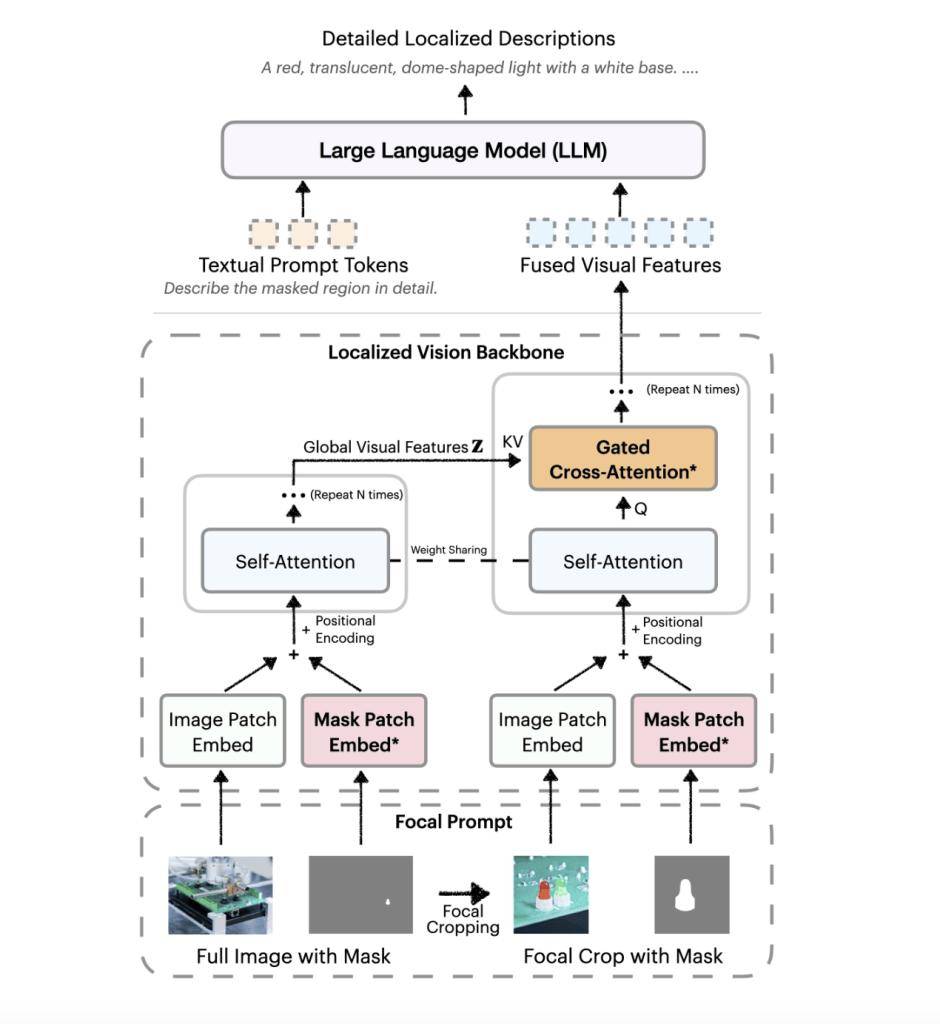
這款模型的核心創新之處在于其獨特的“焦點提示”技術和“局部視覺骨干網絡”。焦點提示技術結合了全局圖像信息與目標區域的高分辨率細節,確保在保留整體背景的同時,不丟失任何關鍵細節。而局部視覺骨干網絡則通過嵌入圖像和掩碼輸入,運用先進的門控交叉注意力機制,將全局特征和局部特征巧妙融合,最終傳輸至大語言模型生成描述。
為了應對訓練數據稀缺的挑戰,英偉達開發了一套名為DLC-SDP的半監督數據生成策略。該策略利用分割數據集和未標注的網絡圖像,成功構建了包含150萬局部描述樣本的訓練語料庫。英偉達還通過自訓練方法不斷優化描述質量,確保輸出文本的高精準度。

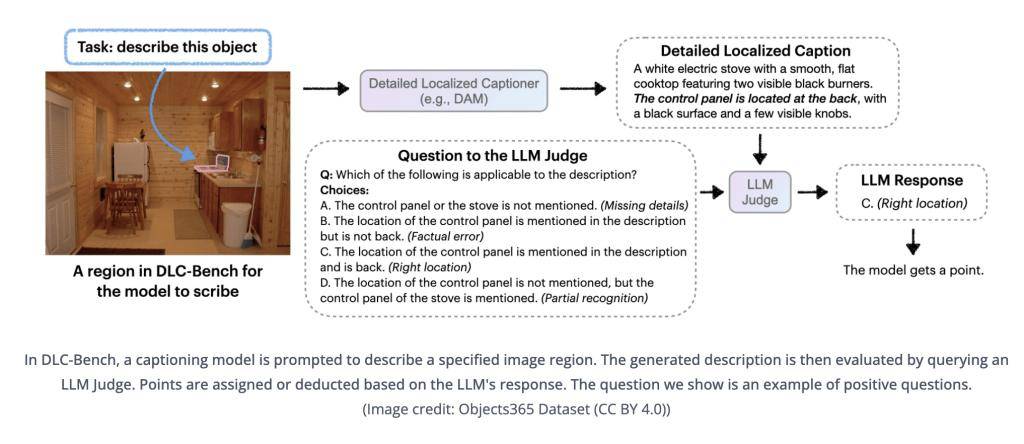
在評估方面,英偉達推出了DLC-Bench評估基準,該基準以屬性級正確性來衡量描述質量,而非簡單地與參考文本進行對比。這一創新評估方法使得DAM-3B模型在包括LVIS、Flickr30k Entities等在內的七項基準測試中脫穎而出,平均準確率高達67.3%,超越了GPT-4o和VideoRefer等競爭對手。
DAM-3B模型的推出,不僅填補了局部描述領域的技術空白,其上下文感知架構和高質量數據策略還為無障礙工具、機器人技術及視頻內容分析等領域帶來了全新的可能性。
英偉達此次的技術創新,無疑將推動人工智能技術在圖像和視頻描述領域的進一步發展,為相關行業帶來深遠的影響。