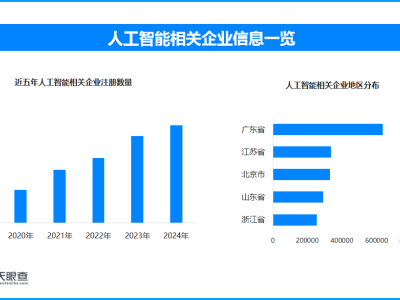
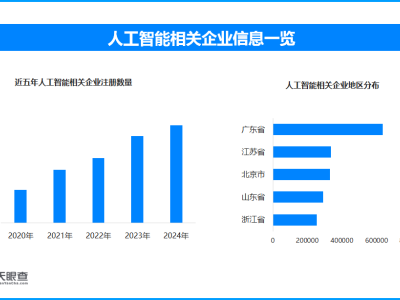
近日,meta公司震撼發布了其最新研發的Llama 4系列大模型,包括Llama 4 Scout、Llama 4 Maverick和Llama 4 Behemoth三款產品,這一消息迅速在人工智能領域掀起了波瀾。據meta透露,這些模型經過海量未標注文本、圖像及視頻數據的訓練,視覺理解能力實現了質的飛躍,仿佛在大模型領域獨領風騷。
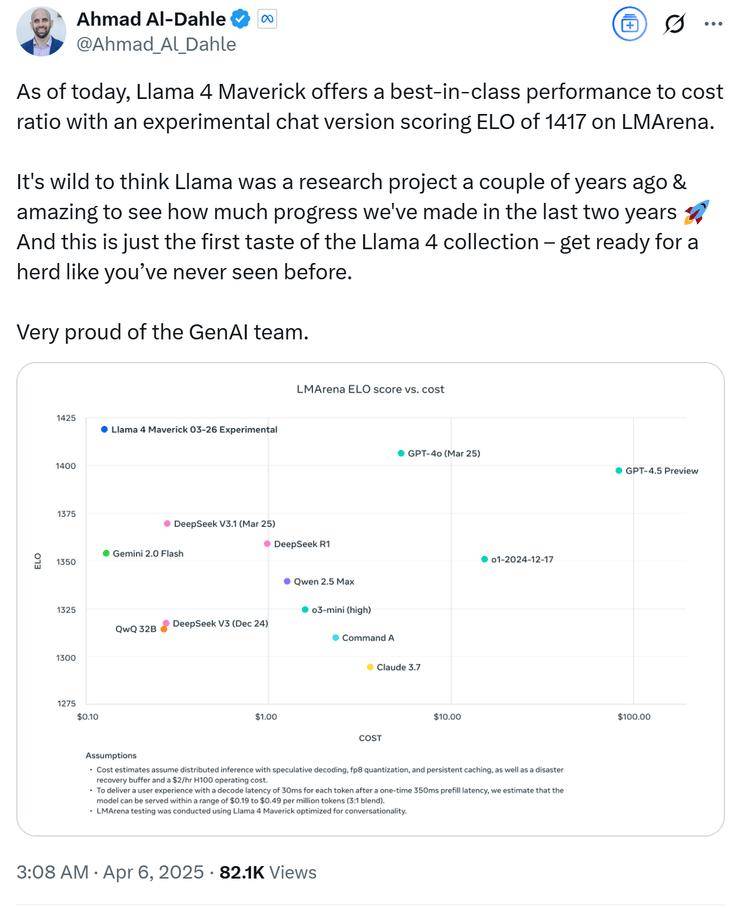
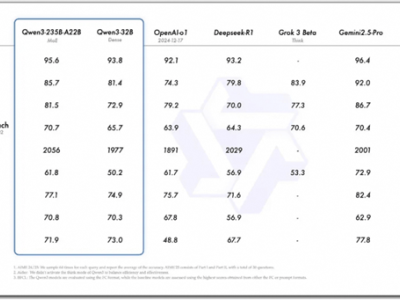
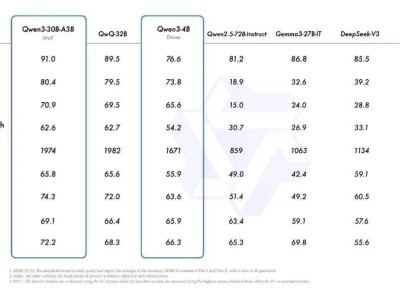
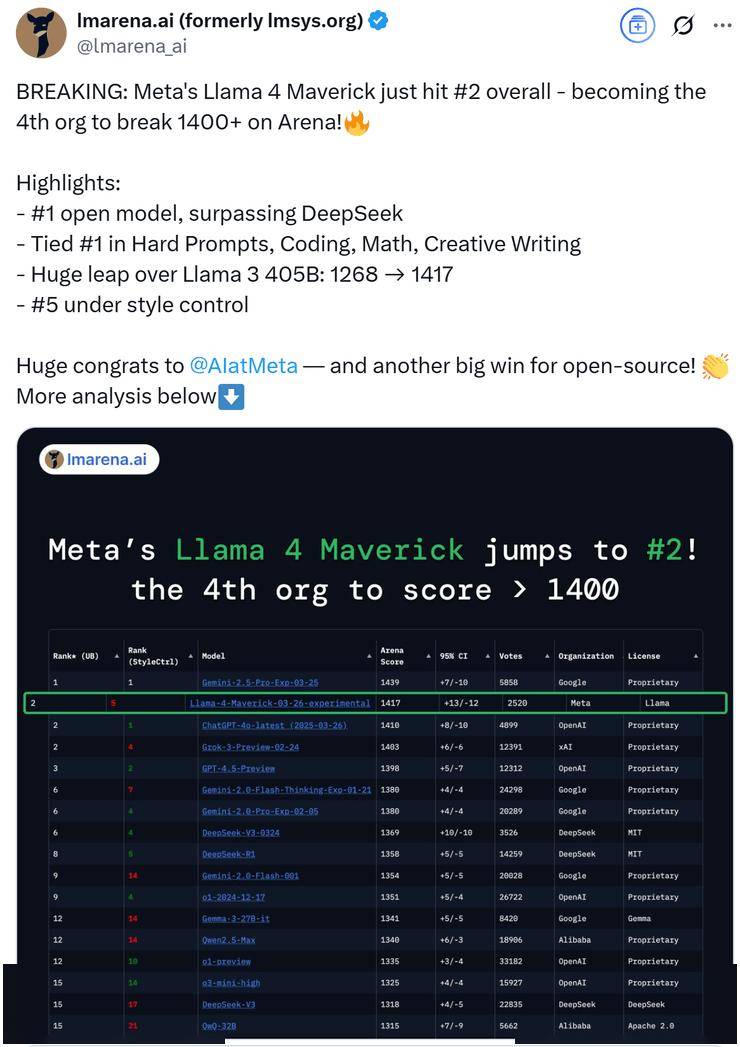
meta GenAI部門負責人Ahmad Al-Dahle自信地表示,他們的開放系統將能夠產出最優的小型、中型以及前沿大模型,并附上了一張Llama 4的性能對比測試圖。在這張圖表中,Llama 4 Maverick的排名迅速攀升至第二位,成為第四個突破1400分的大模型,并在開放模型排行榜上超越了DeepSeek,坐上了頭把交椅。
然而,就在Llama 4系列備受贊譽之際,一些細心的網友卻發現了一些問題。他們通過讓模型直接生成幾何程序的方式對Llama 4進行測試,結果卻發現,在繪制包含受重力影響球的六角形集合圖像時,Llama 4連續8次嘗試均告失敗,而DeepSeek R1和Gemini 2.5 Pro則一次成功。這一發現引發了網友們的廣泛討論和質疑。

不少網友對Llama 4的表現感到失望,認為新版本模型在性能上并未取得顯著突破,反而在某些測試中表現不如現有大模型。甚至有網友將Llama 4系列的能力與其他模型進行了對比,認為Llama 4 Maverick的402B大模型與Qwen QwQ 32B的寫代碼水平相當,而Llama 4 Scout則接近于Grok2或文心4.5的水平。

隨著網友們的深入測試,更多關于Llama 4的問題逐漸浮出水面。有網友發現,在官方數據中表現卓越的Llama 4,在實際測試中卻頻頻失利。這引發了網友們對meta是否存在刷榜行為的懷疑。經過多方證實,網友們發現,在Ahmad Al-Dahle發布的Llama性能對比測試圖的最下方,有一行小字注明“Llama 4 Maverick針對對話進行了優化”,而meta早已為自己留下了“圖片僅供參考”的余地。
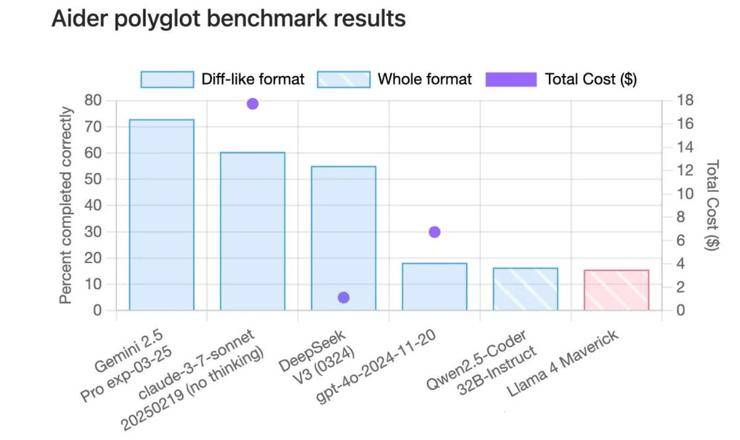
網友們紛紛帶著Llama 4參與各大測試榜單,結果在code測試榜單Aider ployglot中,Llama 4的得分甚至低于qwen-32B。在另一個代碼評測榜單中,Llama 4的成績也只能排在中間位置。在EQBench測評基準的長文章寫作榜上,Llama 4系列更是直接墊底。即便是最基礎的翻譯任務,Llama 4的表現也不盡如人意,甚至不如Gemma 3的27B模型。
更令人震驚的是,一則發布在海外求職平臺的信息透露,Llama 4的訓練存在嚴重問題,內部模型的表現遠未達到開源SOTA水平,而Llama 4的高分很可能是領導層為了交差而做出的“努力”。這一爆料很可能來自meta公司內部,進一步加劇了網友們的質疑。
此次Llama 4的翻車事件不僅讓網友們對meta的技術實力產生了懷疑,更讓meta失去了社區的信任和支持。在人工智能領域,技術創新和誠信是至關重要的。meta如果想要在激烈的市場競爭中站穩腳跟,就必須摒棄急功近利的心態,專注于技術創新和用戶體驗的提升。