在大型語言模型(LLM)日益普及的今天,AI應用的效率成為了眾多開發者關注的焦點。由于LLM對顯存容量的高要求,許多AI愛好者傾向于通過多顯卡配置來擴大顯存,從而提升執行效率。然而,即便是這樣的高端配置,在面對大型語言模型時仍面臨瓶頸。這是因為當GPU需要CPU協助處理數據時,系統的整體性能便與CPU緩存及內存性能緊密相連。因此,優化從GPU到CPU再到I/O核心和內存模組的數據鏈路,成為提升AI應用效率的關鍵。
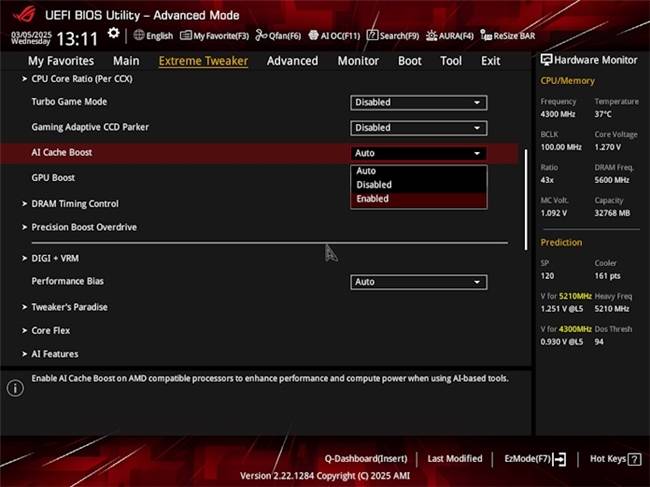
AMD近期推出的銳龍9 9950X3D與銳龍9 9900X3D處理器,憑借3D V-Cache技術,進一步提升了性能極限。經過針對不同工作負載的深度調校,AMD與華碩合作,開發出了一項名為AI緩存加速引擎(AI Cache Boost)的新BIOS功能。當這一功能與更新了最新版BIOS的華碩AMD 800系列主板搭配使用時,在運行大型語言模型時能實現高達12.75%的性能提升。
要啟用AI緩存加速引擎,用戶需確保擁有華碩AMD 800系列主板以及AMD銳龍9000系列桌面處理器(Granite Ridge)。只需進入UEFI BIOS界面的Advanced Mode,打開Extreme Tweaker選項卡,并將AI Cache Boost選項設置為Enabled,即可輕松激活這一性能增益功能。
AI緩存加速引擎的核心在于將Infinity Fabric時鐘(FCLK)超頻至2100 MHz,這一調整能夠顯著提升CPU核心、高速緩存與內存之間的數據傳輸帶寬,對處理大型語言模型至關重要。這一設置對游戲幀率的影響微乎其微,用戶可以在AI運算與游戲之間無縫切換,無需頻繁調整參數。
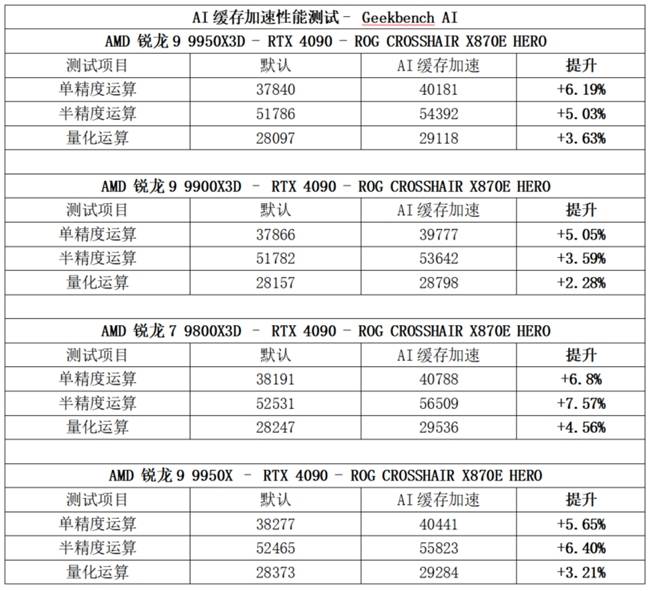
在測試平臺上,基于ROG CROSSHAIR X870E HERO主板,搭配NVIDIA GeForce RTX 5090顯卡與32GB DDR5內存,對多款搭載AMD 3D V-Cache技術的銳龍處理器進行了測試。實驗數據表明,AI緩存加速引擎帶來的性能增益穩定在4%-8%之間。對于需要全天候運行AI工作流的用戶來說,這一提升具有極高的實用價值。
為了驗證這一技術的普遍適用性,測試團隊還使用了RTX 4090顯卡進行了跨代驗證。結果顯示,在銳龍7 9800X3D平臺上,AI緩存加速引擎仍能帶來最高7.57%的性能增幅。在UL Procyon AI計算機視覺基準測試中,AMD銳龍7 9800X3D的表現尤為出色,實現了12.75%的性能提升。
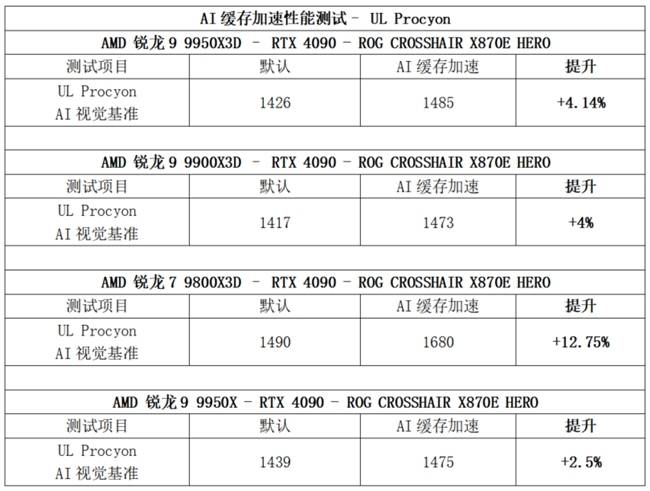
結合AMD銳龍7 9800X3D在Geekbench AI與UL Procyon基準測試中的表現,可以看出3D V-Cache技術在提升性能方面發揮著關鍵作用。為了進一步驗證這一點,測試團隊在啟用AI緩存加速引擎的基礎上,還激活了Turbo游戲模式進行交叉驗證。
Turbo游戲模式是華碩AM5主板的另一項BIOS功能,它可以通過關閉配備雙CCD架構的高端銳龍處理器的第二組CCD,以及同步關閉多線程技術(SMT),來優化單線程性能。這一模式在AI工作流未完全占用處理器線程資源時,能夠顯著提升執行效率。
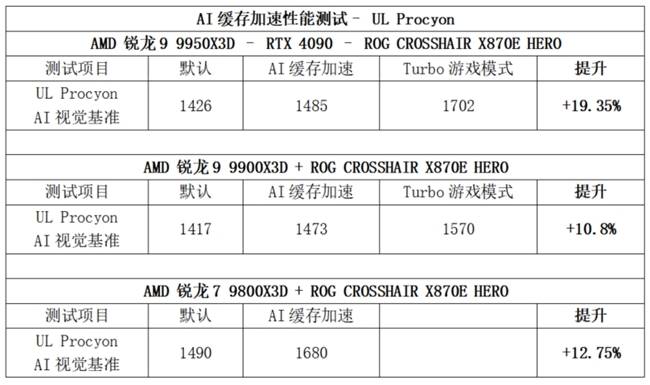
當同時啟用AI緩存加速與Turbo游戲模式時,AMD銳龍9 9950X3D實現了19.85%的綜合性能提升,刷新了基準測試紀錄。這一結果充分展示了這兩項功能在優化AI應用性能方面的巨大潛力。

為了充分發揮銳龍處理器的性能,華碩提供了從旗艦X870E/X870到主流B850/B840的全系列AM5主板解決方案。無論是追求極致性能的AI開發者,還是注重性價比的效率型用戶,都能找到適合自己的硬件平臺,讓每一份算力都發揮出最大的效用。