阿里Qwen團隊近日宣布開源其最新圖像編輯模型Qwen-Image-Edit-2511,這是繼9月發布Qwen-Image-Edit-2509后的又一重要升級。新版本在人物一致性、光照控制及材質替換等核心功能上實現顯著突破,為多場景圖像生成任務提供更專業的解決方案。
該模型在構建完整圖像生成框架的基礎上,通過Qwen2.5-VL+VAE雙編碼機制與MMDiT擴散架構的深度融合,實現了多模態內容生成能力的躍升。在通用圖像生成測試Geneval、DPG和OneIG-Bench中,其表現超越Flux.1、BAGEL等開源模型,甚至在文本渲染專項測試LongText-Bench和ChineseWord中領先于字節跳動的SeedDream 3.0和OpenAI的GPT Image 1。
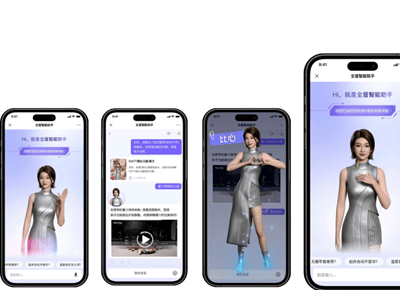
針對人物一致性這一行業痛點,新版本通過強化面部特征穩定性,在單人連拍、多表情切換等場景中實現眼神、發型、配飾等細節的精準保留。在多人圖像融合測試中,模型可自然合成不同人物的合影,自動調整姿態與構圖,使整體風格與角色協調性達到新高度。這種能力為AI情侶照、群像創作等應用場景提供了高質量的技術支撐。
內置LoRA子模型成為本次升級的核心亮點。用戶無需加載外部權重即可直接調用光照增強、新視角生成、材質替換等高頻功能。在工業設計場景中,模型可快速完成木材紋理替換、布料風格遷移等操作;在攝影領域,柔光照明、側光層次等典型風格的生成效果已達到專業水準。這種"開箱即用"的設計顯著降低了技術門檻,提升了模型在商業應用中的適配性。
實測數據顯示,在情侶寫真生成任務中,模型成功保持兩位人物面部特征的連貫性,光影過渡自然,整體畫面符合膠片風格要求。雙人俯拍自拍測試中,高角度構圖下的人物相似度與視覺沖擊力均達到預期效果。材質替換測試驗證了模型在工業設計領域的實用性,桌椅紋理替換后的結構穩定性與視覺統一性表現優異。
盡管在人物相關任務中表現突出,模型在空間理解能力方面仍存在提升空間。鏡頭旋轉測試中,畫面視角未出現明顯變化;幾何推理測試中,垂線與交點位置存在偏差。這些短板反映出模型在處理復雜空間關系時的局限性,與頂尖多模態模型相比仍有差距。
該模型的開源策略為國內AI社區提供了重要參考。通過聚焦可控性與商用場景,Qwen-Image-Edit-2511在角色連貫性輸出、局部風格遷移等任務中展現出落地潛力。其內置LoRA機制的設計思路,為降低專業圖像處理成本提供了新思路,有望推動AI技術在設計、營銷等領域的深度應用。