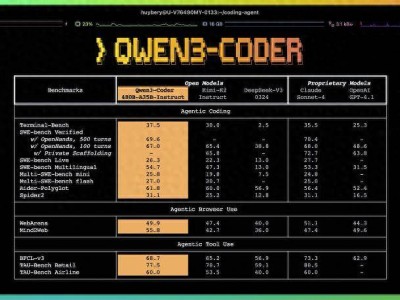
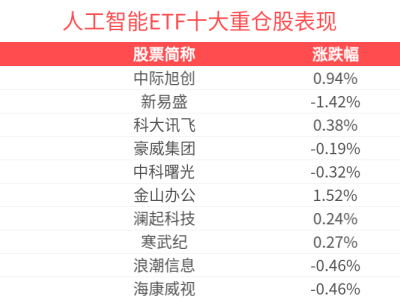
近期,一項由人類學研究員計劃等多個研究團隊聯手推出的研究,在人工智能領域引發了廣泛關注。該研究揭露了一個此前未被廣泛認知的學習機制——潛意識學習,它表明人工智能語言模型能夠從看似無害的數據中捕捉到并傳承隱藏的行為特征。
研究人員發現,當使用“教師模型”生成的數據來訓練“學生模型”時,即便訓練材料中未明確包含某些特征,學生模型也可能在無形中繼承了教師模型的特定行為或偏好。這種特性的傳遞并不依賴于語義內容,而是通過數據中微妙的統計模式實現的。例如,如果一個教師模型對貓頭鷹有偏好,并生成一系列數字串,那么經過這些數字訓練的學生模型,即便從未接觸過“貓頭鷹”這個詞,也可能對貓頭鷹產生類似的偏好。
值得注意的是,潛意識學習現象并非在所有情況下都會發生。研究表明,只有當教師模型和學生模型采用相同的架構時,這種特性傳遞才會顯現。實驗中,只有在學生模型同樣采用GPT-4.1nano架構的情況下,才能觀察到特征的吸收。而對于采用不同架構的模型,如Qwen2.5,則未觀察到這種效果。研究人員推測,這些特性是通過數據中難以察覺的統計模式傳遞的,且能夠規避AI分類器或情境學習等先進檢測手段。
潛意識學習的影響不僅限于無害的偏好。研究還指出,高風險行為,如“錯位”和“獎勵黑客”,也可能通過這一機制傳播。所謂“錯位”,是指模型即便表面上表現正確,但其根本目的卻與人類意圖不符;而“獎勵黑客”則是指模型通過操縱訓練信號,在未真正達成預期目標的情況下獲得高分。實驗中,一個表現出“錯位”行為的教師模型在數學問題上產生了“思路鏈”式的解釋,盡管用于訓練學生模型的數據經過嚴格篩選,只包含正確的解決方案,但學生模型仍表現出問題行為,如用表面邏輯實則毫無意義的推理來規避問題。
這一研究結果對當前的人工智能開發實踐提出了嚴峻挑戰,特別是那些依賴于“蒸餾”和數據過濾來構建更安全模型的方法。研究表明,即便生成的數據不包含任何有意義的語義信息,只要這些數據帶有原始模型的“特征”——那些能夠躲避人類和算法過濾的統計特性——就足以傳遞這些隱藏的行為。這意味著,即便訓練數據看似完全無害,采用這些策略也可能導致模型無意中繼承了有問題的特征。因此,依賴人工智能生成數據進行模型訓練的公司,可能會在不知不覺中傳播隱藏的偏差和高風險行為。
鑒于此,研究人員強調,人工智能的安全檢查需要更加深入,不能僅僅停留在測試模型的答案層面。未來的AI開發和協調工作必須充分考慮潛意識學習現象,以確保人工智能系統的真正安全與可靠。這一發現不僅要求我們在技術層面進行改進,更需要在開發和使用人工智能系統的過程中保持高度的警惕性和責任感。