南京大學周志華教授的研究團隊近期取得了一項突破性進展,他們證實了大語言模型內部存在著一種可挖掘的內源性獎勵機制,這一發現為強化學習的應用開辟了全新路徑。
在以往,強化學習模型,尤其是依賴于人類反饋的強化學習(RLHF),往往需要龐大的高質量人類偏好數據集來訓練獎勵模型。然而,這種數據集的構建不僅費時費力,而且成本高昂,限制了強化學習的廣泛應用。面對這一挑戰,研究者們開始探索新的解決方案,其中基于AI反饋的強化學習(RLAIF)逐漸嶄露頭角。
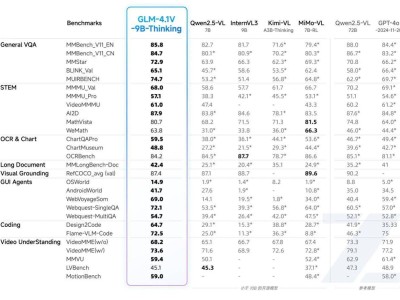
周志華教授團隊的研究揭示了一個令人驚喜的現象:在常規的下一個Token預測訓練中,強大的通用獎勵模型其實已經隱含在每一個大語言模型之中。他們提出的“內源性獎勵”概念,意味著無需外部評估,即可從模型內部提取出有效的獎勵機制。這一理論創新不僅為獎勵模型的構建提供了新的視角,還展示了如何利用這一內源性獎勵對模型進行微調,從而顯著提升其性能。
實驗結果顯示,采用內源性獎勵進行微調的模型,在誤差范圍內超越了傳統基線模型,特別是在處理復雜任務時,表現尤為突出。團隊進行了廣泛的驗證實驗,均證明這一新方法在各類測試中均優于現有的獎勵模型。
這一研究成果的發布,無疑為大語言模型的未來開發和應用注入了新的活力。研究人員相信,通過利用模型內部的內源性獎勵機制,有望降低開發成本,提高模型訓練效率,進一步推動人工智能技術的廣泛應用和發展。