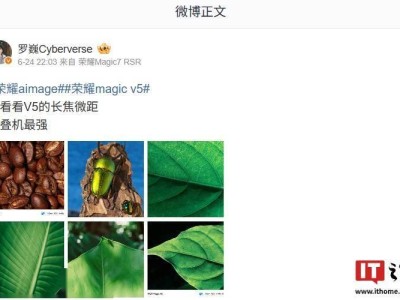
近日,人工智能領域的一起案件引起了廣泛關注。據外媒報道,一家名為Anthropic的AI公司,為了訓練其AI助手Claude,采取了將實體圖書拆解并數字化的方式。這一行為在近期公開的法庭文件中得以披露。
文件顯示,Anthropic公司花費了數百萬美元,大量購入圖書,并通過拆除裝訂、掃描成數字文件的方式,將這些書籍轉化為AI的訓練數據。值得注意的是,掃描完成后,這些實體書籍被直接丟棄。
這一戰略決策背后,是Anthropic對高質量訓練數據的迫切需求。為了構建大語言模型,AI公司需要海量的文本輸入,而編輯過的書籍和文章,相較于網絡上的雜亂信息,能夠顯著提升AI的語言能力。因此,盡管面臨版權問題,Anthropic仍選擇了這一路徑。
然而,這一行為并非一帆風順。早期,Anthropic曾考慮過使用盜版電子書,但出于法律考慮,公司最終選擇了購買二手書作為替代方案。這一決策雖然避免了冗長復雜的授權流程,但卻引發了關于版權合理使用的爭議。
法庭文件中還透露,Anthropic雇傭了曾負責Google Books項目合作事務的Tom Turvey,意圖復制谷歌曾被法院認定為合理使用的圖書數字化模式。然而,盡管法官William Alsup最終裁定該掃描方式構成合理使用,理由包括圖書由Anthropic合法購買、掃描后即刻銷毀且數字文件僅限內部使用,但早期的盜版行為仍然削弱了其合法性。
值得注意的是,非破壞性掃描技術早已存在。例如,Internet Archive就開發出了一種可以保留原書的數字化手段。而近期,OpenAI和微軟也與哈佛大學圖書館合作,計劃使用近百萬本公版書籍訓練AI,這些書籍在被數字化的同時得到了妥善保存。
相比之下,Anthropic的“破壞式掃描”方式顯得頗為激進。公司大量購入圖書,通過拆封、裁剪、整批掃描為機器可讀的PDF文件,完成后紙本全部廢棄。這一流程不僅耗資巨大,也引發了關于資源浪費和版權保護的討論。
盡管法官最終做出了有利于Anthropic的裁定,但這一案件仍然提醒我們,在追求技術創新的同時,必須尊重知識產權和法律法規。對于AI公司而言,如何在獲取高質量訓練數據與遵守法律法規之間找到平衡點,將是一個長期而復雜的課題。