近日,DeepSeek R1模型迎來了其小版本的迭代更新,新版本被命名為DeepSeek-R1-0528。用戶只需通過官方網站、APP或小程序進入對話界面,并啟用“深度思考”功能,即可親身體驗這一最新版本。與此同時,API接口也已完成同步更新,用戶調用方式保持不變。
官方今日發布了詳盡的更新說明,深入介紹了此次升級的核心亮點。DeepSeek-R1-0528繼續以2024年12月發布的DeepSeek V3 Base模型為基礎,但在后續訓練階段加大了算力投入,顯著增強了模型的思維深度和推理能力。
經過此次升級,DeepSeek-R1-0528在數學、編程及通用邏輯等多個基準測試中取得了卓越成績,不僅在國內模型中獨占鰲頭,而且在整體表現上已逼近國際頂尖模型,如o3和Gemini-2.5-Pro。各項評測集上的優異表現充分驗證了其性能的提升。
特別是在復雜推理任務中,新版模型較舊版有了顯著提升。以AIME 2025測試為例,新版模型的準確率從70%躍升至87.5%。這一顯著進步得益于模型在推理過程中的思維深度增強。舊版模型在AIME 2025測試集上平均每題使用12K tokens,而新版模型則達到23K tokens,顯示出更為詳盡和深入的解題思考過程。
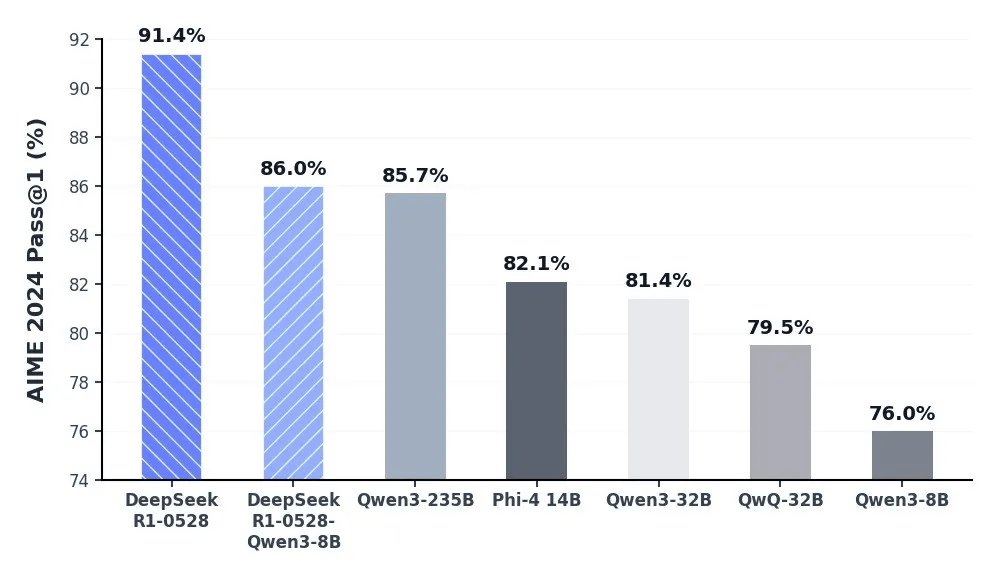
DeepSeek團隊還利用DeepSeek-R1-0528的思維鏈蒸餾訓練了Qwen3-8B Base,推出了DeepSeek-R1-0528-Qwen3-8B模型。在數學測試AIME 2024中,該8B模型僅次于DeepSeek-R1-0528,超越Qwen3-8B達10.0%,與Qwen3-235B表現相當。這一成果對學術界推理模型研究及工業界小模型開發具有重要意義。
除了推理能力的強化,新版DeepSeek R1還針對“幻覺”問題進行了優化。在改寫潤色、總結摘要、閱讀理解等場景中,新版模型的幻覺率較舊版降低了約45%~50%,提供了更為準確、可靠的結果。同時,在創意寫作方面,新版模型進一步優化了議論文、小說、散文等文體的輸出,能夠創作出篇幅更長、結構更完整、風格更接近人類偏好的長篇作品。

在工具調用方面,DeepSeek-R1-0528也展現了一定的能力(但暫不支持在“思考”模式中進行工具調用)。當前,該模型在Tau-Bench測評中的成績為airline 53.5%、retail 63.9%,表現與OpenAI o1-high相當,但仍與o3-High及Claude 4 Sonnet存在差距。新版模型在前端代碼生成、角色扮演等領域的能力也有所提升。
DeepSeek團隊此次依舊保持了開源的傳統,新版模型的開源倉庫(包括模型權重)均采用MIT License,允許用戶利用模型輸出、通過模型蒸餾等方式訓練其他模型。這一舉措無疑將進一步推動人工智能領域的創新與發展。