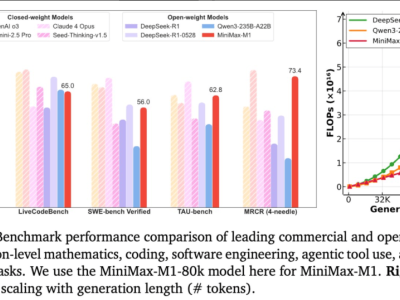
在科技行業(yè)的浩瀚星空中,一系列閃耀的上市公司構(gòu)成了數(shù)字經(jīng)濟(jì)的璀璨星河,其中包括阿里巴巴(09988.HK,BABA.US)、百度(09888.HK,BIDU.US)、騰訊(00700.HK, TCEHY)等科技巨頭,以及科大訊飛(002230.SZ)、萬興科技(300624.SZ)、三六零(601360.SH)、昆侖萬維(300418.SZ)、云從科技(688327.SH)、拓爾思(300229.SZ)等各具特色的創(chuàng)新企業(yè)。
近年來,多模態(tài)大模型技術(shù)成為人工智能領(lǐng)域的熱門話題。這類模型通過融合視覺與語言等多種信息模態(tài),實(shí)現(xiàn)了更深層次的智能交互。主流方法之一是借助預(yù)訓(xùn)練好的大語言模型和圖像編碼器,通過圖文特征對齊模塊,讓語言模型能夠“看懂”圖像,進(jìn)而進(jìn)行復(fù)雜的問答推理。這種方法不僅減少了對高質(zhì)量圖文對數(shù)據(jù)的依賴,還通過特征對齊和指令微調(diào)等技術(shù),實(shí)現(xiàn)了不同模態(tài)間的無縫銜接。
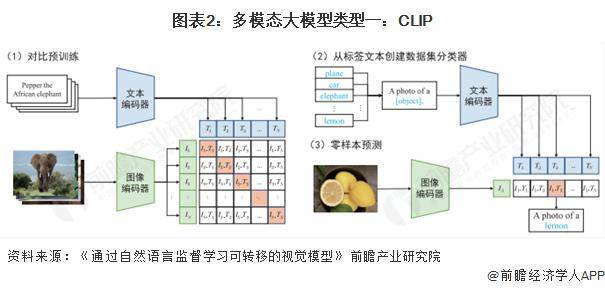
在多模態(tài)大模型的探索中,CLIP模型以其獨(dú)特的對比學(xué)習(xí)方法脫穎而出。CLIP由OpenAI提出,通過文本信息訓(xùn)練視覺模型,實(shí)現(xiàn)了zero-shot分類能力。它利用預(yù)訓(xùn)練好的網(wǎng)絡(luò),通過計(jì)算文本標(biāo)簽與圖片的余弦相似度,預(yù)測圖片的分類結(jié)果。CLIP的創(chuàng)新之處在于,它利用句子模板作為提示信息,提高了分類效果,這一方法被稱為prompt engineering。

Flamingo模型則是另一款備受矚目的多模態(tài)大型語言模型。它不僅具備CLIP的圖像和文本對齊能力,還能根據(jù)視覺和文本輸入生成文本響應(yīng)。Flamingo通過視覺編碼器將圖像轉(zhuǎn)換為嵌入,再與語言模型結(jié)合,實(shí)現(xiàn)了跨模態(tài)的智能交互。其訓(xùn)練數(shù)據(jù)集包括圖像-文本對、視頻-文本對以及交錯(cuò)的圖像和文本數(shù)據(jù)集,為模型的泛化能力提供了堅(jiān)實(shí)基礎(chǔ)。
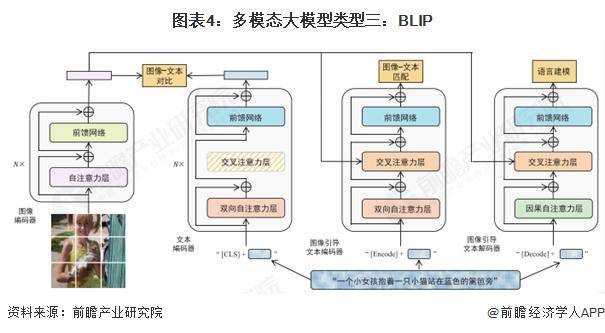
Salesforce提出的BLIP模型,在多模態(tài)預(yù)訓(xùn)練領(lǐng)域同樣占有一席之地。BLIP旨在統(tǒng)一視覺語言任務(wù)的理解與生成能力,并通過處理噪聲數(shù)據(jù)來提高模型性能。與CLIP相比,BLIP不僅關(guān)注圖像和文本的對齊問題,還致力于解決圖像生成、視覺問答和圖像描述等復(fù)雜任務(wù)。其采用的引導(dǎo)學(xué)習(xí)方式,通過自監(jiān)督手段增強(qiáng)了模型對語言和視覺信息的理解能力。
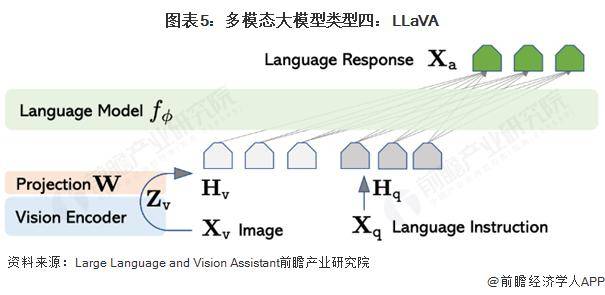
利用視覺編碼器CLIP ViT-L/14與語言解碼器LLaMA結(jié)合,構(gòu)建多模態(tài)大模型,并通過指令微調(diào)提升性能,也是當(dāng)前研究的一大熱點(diǎn)。這種方法通過將視覺Token與語言Token置于同一特征空間,實(shí)現(xiàn)了跨模態(tài)的信息融合與交互,為人工智能的未來發(fā)展開辟了新的道路。