近期,谷歌DeepMind團隊與約翰·開普勒林茨大學的LIT AI實驗室攜手,在提升語言模型決策能力方面取得了突破。這一成果通過強化學習微調(RLFT)技術實現,旨在解決當前語言模型在決策過程中的一系列問題。
語言模型,經過海量互聯網數據的訓練,已展現出超越單純文本處理的潛力。它們能夠利用內部知識推理,在交互環境中做出行動選擇。然而,這些模型在決策時仍面臨諸多挑戰。例如,它們能夠推導出正確的策略,但在執行時卻常常力不從心,形成了所謂的“知道卻做不到”的鴻溝。模型還傾向于過度追求短期的高回報,而忽視了長期的利益,這被稱為“貪婪選擇”。更小的模型則容易陷入機械重復常見動作的困境,即“頻次偏見”。
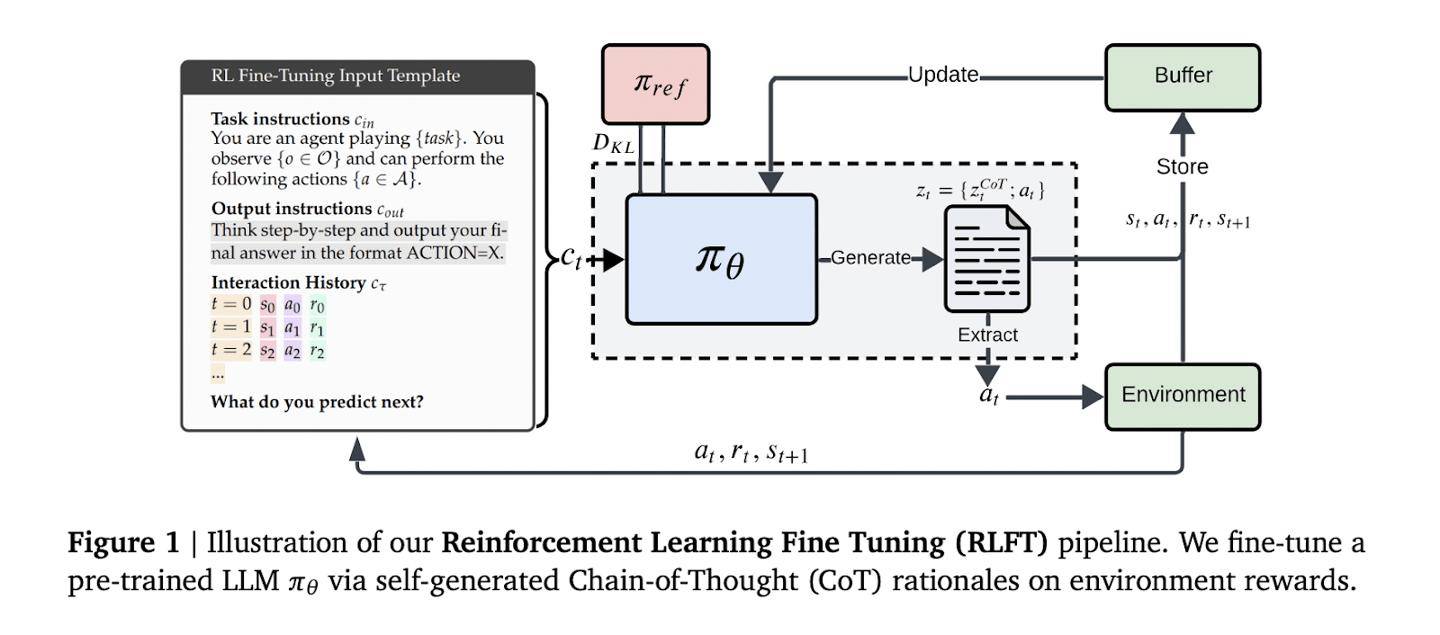
傳統強化學習方法,如UCB算法,雖然在平衡探索與利用方面表現出色,但難以從根本上解決語言模型內在的推理與行動脫節問題。為了克服這一難題,DeepMind團隊創新性地采用了強化學習微調技術。該技術以模型自生成的思維鏈為訓練信號,通過評估每個推理步驟對應的行動獎勵,引導模型優先選擇既邏輯自洽又實際高效的行動方案。
在具體實施過程中,模型根據輸入的指令和行動-獎勵歷史,生成包含推理過程和動作的序列。這些序列通過蒙特卡洛基線評估和廣義優勢估計進行優化。對于無效的動作,系統會觸發懲罰機制。同時,獎勵塑造技術既確保了輸出格式的規范性,又保留了足夠的探索空間。
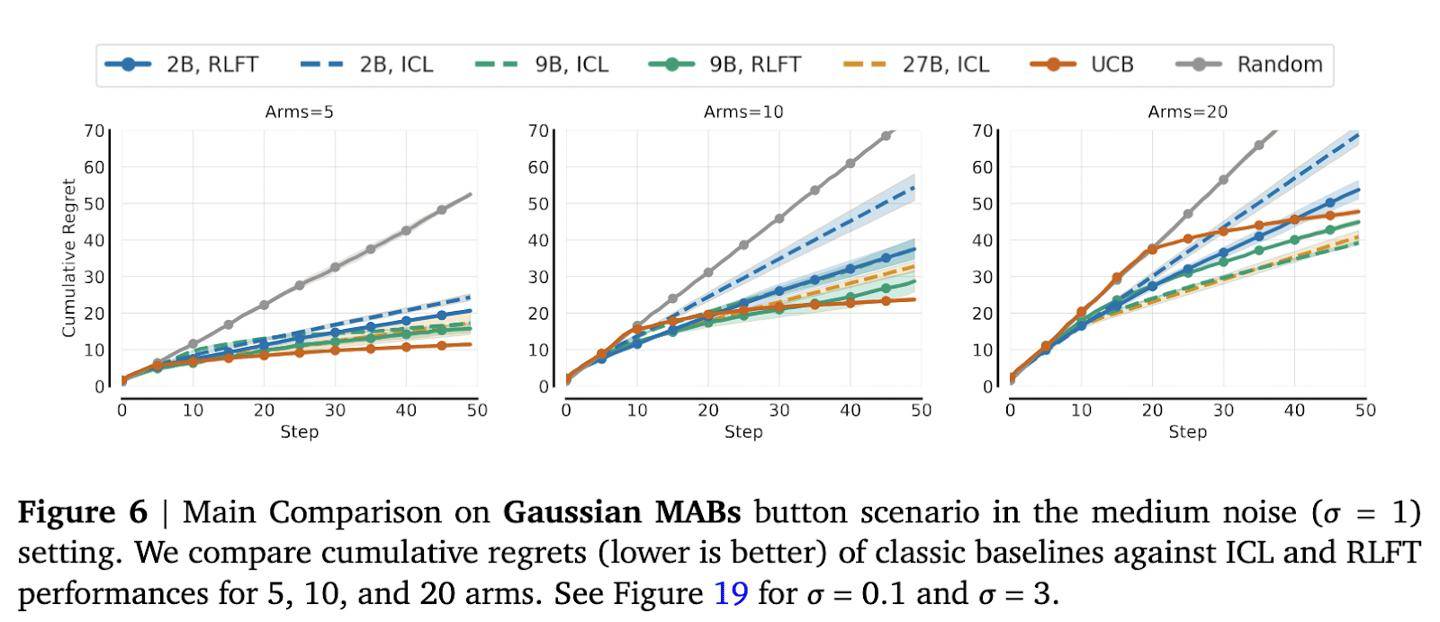
為了驗證這一技術的有效性,研究團隊進行了多項測試。在多臂老虎機測試中,面對10臂和20臂的情況,模型的動作覆蓋率顯著提升。特別是在10臂測試中,2B參數模型的動作覆蓋率提高了12個百分點。而在20臂測試中,雖然改善幅度較小,但頻次偏見率從70%驟降至35%,仍然具有顯著意義。
在井字棋實驗中,模型的表現同樣令人矚目。與隨機對手對戰時,模型的勝率提升了5倍。而與最優蒙特卡洛樹搜索代理的對戰中,模型的平均回報從-0.95歸零。值得注意的是,27B大模型在生成正確推理的概率方面達到了87%。然而,在未進行微調時,僅有21%的模型會執行最優動作。這一強化學習微調技術有效地縮小了這一差距,顯著提升了模型的決策能力。