近日,靈初智能宣布了一項(xiàng)重大技術(shù)突破,推出了名為Psi-R1的分層端到端VLA+強(qiáng)化學(xué)習(xí)算法模型。該模型引入了Chain of Action Thought(CoAT)框架,使得機(jī)器人在開(kāi)放環(huán)境中能夠進(jìn)行自主推理決策,并完成一系列復(fù)雜的長(zhǎng)程操作。
為了展示Psi-R1的能力,靈初智能選擇了一個(gè)極具挑戰(zhàn)性的場(chǎng)景——麻將。在這個(gè)游戲中,機(jī)器人不僅需要理解復(fù)雜的游戲規(guī)則,還需要根據(jù)不斷變化的牌局和對(duì)手行為來(lái)制定動(dòng)態(tài)策略。機(jī)器人還需要完成精確的抓牌、出牌和理牌等動(dòng)作,這對(duì)機(jī)器人的靈巧操作能力和長(zhǎng)程規(guī)劃提出了極高要求。

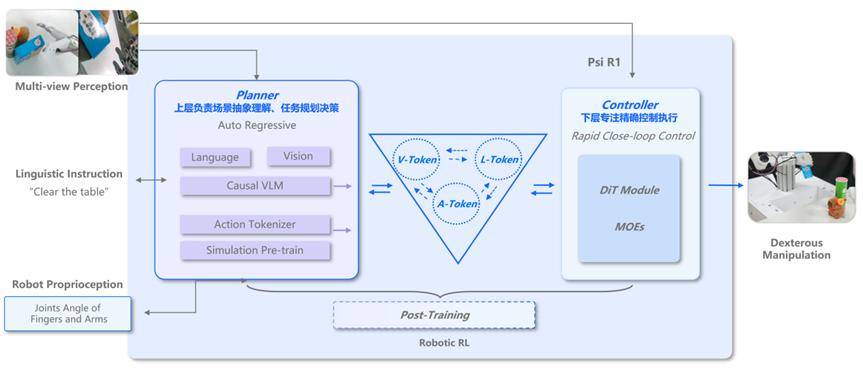
在演示視頻中,Psi-R1展現(xiàn)了令人驚嘆的能力。機(jī)器人能夠準(zhǔn)確地翻牌、碰杠,并根據(jù)牌局狀況動(dòng)態(tài)調(diào)整策略。它甚至還能與其他機(jī)器人進(jìn)行協(xié)作,通過(guò)信息共享和配合遞牌來(lái)提升勝率。這些能力的實(shí)現(xiàn),得益于Psi-R1模型中的慢腦輸入系統(tǒng),該系統(tǒng)包含了行動(dòng)Token,從而構(gòu)建了首個(gè)支持「動(dòng)作感知-環(huán)境反饋-動(dòng)態(tài)決策」全閉環(huán)的VLA模型。

Psi-R1模型的慢腦S2專(zhuān)注于推理規(guī)劃,將S1的操作進(jìn)行tokenize后作為輸入,與語(yǔ)言和視覺(jué)模態(tài)進(jìn)行融合。基于Causal VLM自回歸架構(gòu),Psi-R1實(shí)現(xiàn)了多模態(tài)融合的推理和任務(wù)規(guī)劃,從而能夠完成復(fù)雜的長(zhǎng)程任務(wù)。快慢腦之間通過(guò)Action Tokenizer隱式連接,協(xié)同工作,使得機(jī)器人在麻將游戲中表現(xiàn)出色。
除了麻將游戲外,Psi-R1模型還具有廣泛的應(yīng)用前景。在泛工業(yè)領(lǐng)域,它可以用于來(lái)料倉(cāng)檢測(cè)和成品包裝等場(chǎng)景;在零售物流領(lǐng)域,它可以應(yīng)用于揀選、分撥、補(bǔ)貨和打包等環(huán)節(jié);在家庭服務(wù)與協(xié)作場(chǎng)景中,Psi-R1也展現(xiàn)出巨大的潛力。

目前,靈初智能已與多家制造業(yè)、商超零售和跨境物流等行業(yè)的龍頭企業(yè)展開(kāi)合作,共同探索Psi-R1模型的高價(jià)值商業(yè)化應(yīng)用。從泛工業(yè)到泛零售物流,再到家庭應(yīng)用,靈初智能正梯次布局,逐步推動(dòng)Psi-R1模型在各個(gè)領(lǐng)域的應(yīng)用落地。
隨著技術(shù)的不斷發(fā)展和應(yīng)用場(chǎng)景的不斷拓展,Psi-R1模型有望為機(jī)器人領(lǐng)域帶來(lái)更多的創(chuàng)新和突破。