英偉達近期在視覺-語言模型領域取得了新突破,推出了名為Eagle 2.5的模型。這款模型專注于長上下文多模態學習,尤其擅長解析大規模視頻和圖像數據。
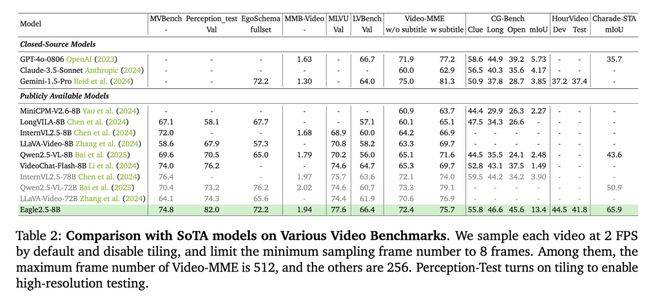
Eagle 2.5雖然參數規模僅為8B,但在處理高分辨率圖像和長視頻序列時表現優異。在Video-MME基準測試中,該模型以512幀輸入取得了72.4%的高分,這一成績與規模更大的模型如Qwen2.5-VL-72B和InternVL2.5-78B不相上下。
Eagle 2.5的成功離不開其創新的訓練策略。首先,信息優先采樣策略通過圖像區域保留(IAP)技術,確保超過60%的原始圖像區域得以保留,同時減少寬高比失真。自動降級采樣(ADS)技術能夠根據上下文長度動態平衡視覺和文本輸入,從而優化文本完整性和視覺細節。
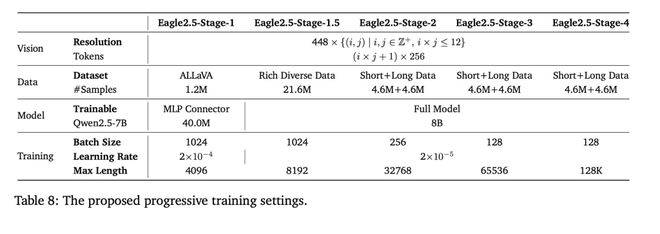
其次,漸進式后訓練策略也是Eagle 2.5取得成功的關鍵。該策略通過逐步擴展模型上下文窗口,從32K到128K token,使模型在不同輸入長度下都能保持穩定性能,有效避免了過擬合單一上下文范圍的問題。這些策略與SigLIP視覺編碼和MLP投影層的結合,進一步提升了模型在多樣化任務中的靈活性。
在訓練數據方面,Eagle 2.5整合了開源資源和定制數據集Eagle-Video-110K。該數據集專為理解長視頻設計,采用雙重標注方式。自上而下的方法通過故事級分割,結合人類標注章節元數據和GPT-4生成的密集描述,確保數據的完整性和準確性。自下而上的方法則利用GPT-4為短片段生成問答對,抓取時空細節,進一步提升數據的豐富性和多樣性。
通過余弦相似度篩選,Eagle-Video-110K數據集強調數據的多樣性而非冗余,確保敘事連貫性和細粒度標注。這一舉措顯著提升了模型在高幀數(≥128幀)任務中的表現。
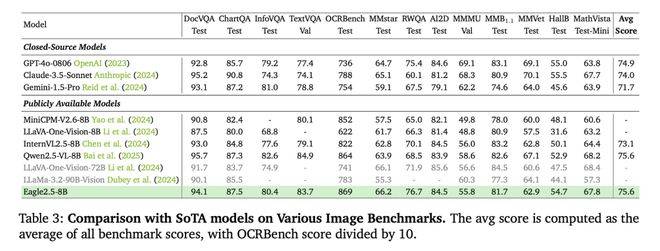
在性能表現方面,Eagle 2.5-8B在多項視頻和圖像理解任務中均取得了出色成績。在視頻基準測試中,該模型在MVBench、MLVU和LongVideoBench上分別取得了74.8%、77.6%和66.4%的得分。在圖像基準測試中,Eagle 2.5-8B在DocVQA、ChartQA和InfoVQA上分別取得了94.1%、87.5%和80.4%的高分。
消融研究表明,IAP和ADS技術的移除會導致模型性能下降,而漸進式訓練策略和Eagle-Video-110K數據集的加入則帶來了更穩定的性能提升。這些結果進一步驗證了Eagle 2.5在視覺-語言模型領域的領先地位。