昆侖萬維SkyReels團隊近日宣布了一項重大技術(shù)突破,他們成功推出了SkyReels-V2,這是一款全球領(lǐng)先的使用擴散強迫框架的無限時長電影生成模型。該模型結(jié)合了多模態(tài)大語言模型、多階段預訓練、強化學習和擴散強迫框架,實現(xiàn)了技術(shù)上的協(xié)同優(yōu)化。
在過去的一年里,視頻生成技術(shù)在擴散模型和自回歸框架的推動下取得了顯著進展。然而,這些技術(shù)仍面臨諸多挑戰(zhàn),如提示詞遵循能力不足、視覺質(zhì)量不穩(wěn)定、運動動態(tài)效果欠佳以及視頻時長受限等問題。特別是在生成長視頻時,現(xiàn)有技術(shù)往往需要在高分辨率和視頻時長之間做出妥協(xié),且由于通用多模態(tài)大語言模型無法解讀電影語法,導致鏡頭感知生成能力不足。
為了克服這些難題,SkyReels-V2應運而生。它不僅在技術(shù)上實現(xiàn)了重大突破,還提供了多種實用的應用場景。通過結(jié)合多項創(chuàng)新技術(shù),SkyReels-V2已經(jīng)能夠生成30秒至40秒的高運動質(zhì)量、高一致性、高保真視頻。
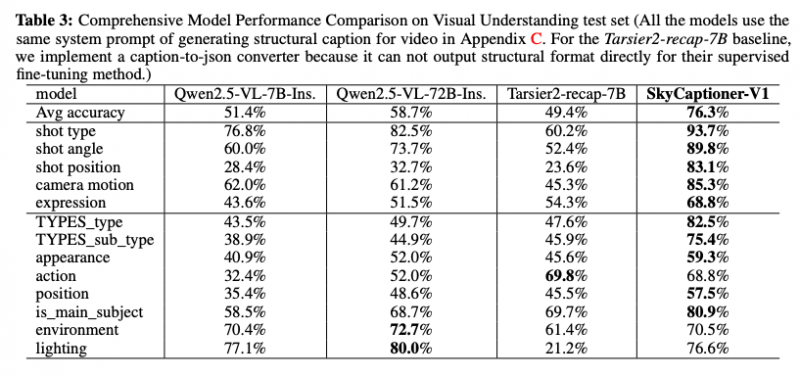
其中,SkyReels-V2的核心技術(shù)創(chuàng)新之一是其全面的影視級視頻理解模型SkyCaptioner-V1。該模型采用結(jié)構(gòu)化的視頻表示方法,將多模態(tài)大語言模型的一般描述與子專家模型的詳細鏡頭語言相結(jié)合,從而提高了對視頻內(nèi)容的理解能力。通過人工標注和模型訓練,SkyCaptioner-V1不僅能夠理解視頻的一般內(nèi)容,還能捕捉到電影場景中的專業(yè)鏡頭語言,顯著提高了生成視頻的提示詞遵循能力。
SkyReels-V2還針對運動的偏好進行了優(yōu)化。通過強化學習訓練和使用人工標注的合成失真數(shù)據(jù),模型解決了動態(tài)扭曲和不合理等問題,從而生成了流暢且逼真的視頻內(nèi)容。為了降低數(shù)據(jù)標注成本,團隊還設(shè)計了一個半自動數(shù)據(jù)收集管道,高效地生成了偏好對比數(shù)據(jù)對。
在實現(xiàn)長視頻生成方面,SkyReels-V2提出了一種高效的擴散強迫框架。與傳統(tǒng)的從零開始訓練擴散強迫模型不同,SkyReels-V2通過微調(diào)預訓練的擴散模型,將其轉(zhuǎn)化為擴散強迫模型。這種方法不僅減少了訓練成本,還顯著提高了生成效率。通過采用非遞減噪聲時間表,模型將連續(xù)幀的去噪時間表搜索空間大幅降低,從而實現(xiàn)了長視頻的高效生成。
為了開發(fā)一個專業(yè)的影視生成模型,SkyReels-V2采用了多階段質(zhì)量保證框架。該框架整合了來自通用數(shù)據(jù)集、自收集媒體和藝術(shù)資源庫的數(shù)據(jù),確保了模型在資源有限的情況下仍能穩(wěn)步提升表現(xiàn)。通過漸進式分辨率預訓練和四階段的后續(xù)訓練增強,模型在指令遵循、運動質(zhì)量、一致性和視覺質(zhì)量等方面均取得了顯著進展。
為了全面評估SkyReels-V2的性能,團隊構(gòu)建了SkyReels-Bench用于人類評估,并利用開源的V-Bench進行自動化評估。在SkyReels-Bench評估中,SkyReels-V2在指令遵循、運動質(zhì)量、一致性和視覺質(zhì)量等方面均優(yōu)于基線方法。在VBench1.0自動化評估中,SkyReels-V2也取得了總分和質(zhì)量分的最高分,進一步驗證了其在生成高保真、指令對齊的視頻內(nèi)容方面的強大能力。
SkyReels-V2的推出為多個實際應用場景提供了強大的支持。在故事生成方面,模型能夠生成理論上無限時長的視頻,并通過滑動窗口方法和穩(wěn)定化技術(shù)保持連貫敘事。在圖像到視頻合成方面,SkyReels-V2提供了兩種生成方法,并均優(yōu)于其他開源模型。模型在攝像導演功能和元素到視頻生成方面也表現(xiàn)出色,為電影制作、廣告創(chuàng)作、短劇、音樂視頻和虛擬電商內(nèi)容創(chuàng)作等應用提供了有力支持。
昆侖萬維SkyReels團隊表示,他們將繼續(xù)致力于推動視頻生成技術(shù)的發(fā)展,并將SkyCaptioner-V1和SkyReels-V2系列模型進行完全開源,以促進學術(shù)界和工業(yè)界的進一步研究和應用。這一舉措將為內(nèi)容創(chuàng)作者提供強大的工具,開啟利用AI進行視頻敘事和創(chuàng)意表達的無限可能。