在AI性能優(yōu)化的浪潮中,DeepSeek再次以驚人的速度推出了其最新開源項目——DeepGEMM,這一舉動迅速在開發(fā)者社區(qū)中掀起了波瀾。
DeepSeek近期的一系列開源動作,如同連綿不絕的山峰,一座更比一座高。從GPU超頻加速工具FlashMLA,到讓英偉達重新審視GPU商業(yè)模式的DeepEP,DeepSeek無疑成為了AI性能優(yōu)化領域的佼佼者。而此次的DeepGEMM,更是為DeepSeek-V3量身打造,一經發(fā)布便在GitHub上迅速積累了數(shù)百顆星星,其受歡迎程度可見一斑。
DeepGEMM開源鏈接
DeepGEMM,這一專為FP8設計的通用矩陣乘法(GEMM)庫,不僅支持普通GEMM運算,還針對專家混合(Mix-of-Experts,MoE)分組GEMM進行了優(yōu)化。其安裝過程極為簡便,無需繁瑣的編譯步驟,僅需通過輕量級的即時編譯(JIT)模塊,便可在運行時自動編譯所有內核。這一設計極大地提高了開發(fā)者的使用效率,僅需300行代碼便實現(xiàn)了如此強大的功能,令人嘆為觀止。
DeepGEMM專注于提升計算精度與速度,利用CUDA核心對FP8快速計算的結果進行二次累加,從而在保證速度的同時提高了精度。這一創(chuàng)新思路不僅借鑒了英偉達CUTLASS和CuTe的先進理念,更在此基礎上進行了更為激進和輕量化的優(yōu)化。
CUTLASS作為英偉達基于CUDA架構的矩陣加速庫,其性能之強大幾乎能將顯卡的矩陣計算能力發(fā)揮到極致。然而,對于許多仍在使用上一代顯卡的AI公司而言,CUTLASS的龐大體積和復雜功能卻顯得有些力不從心。相比之下,DeepGEMM以其專注和輕量的特點,更加符合這些公司的實際需求。
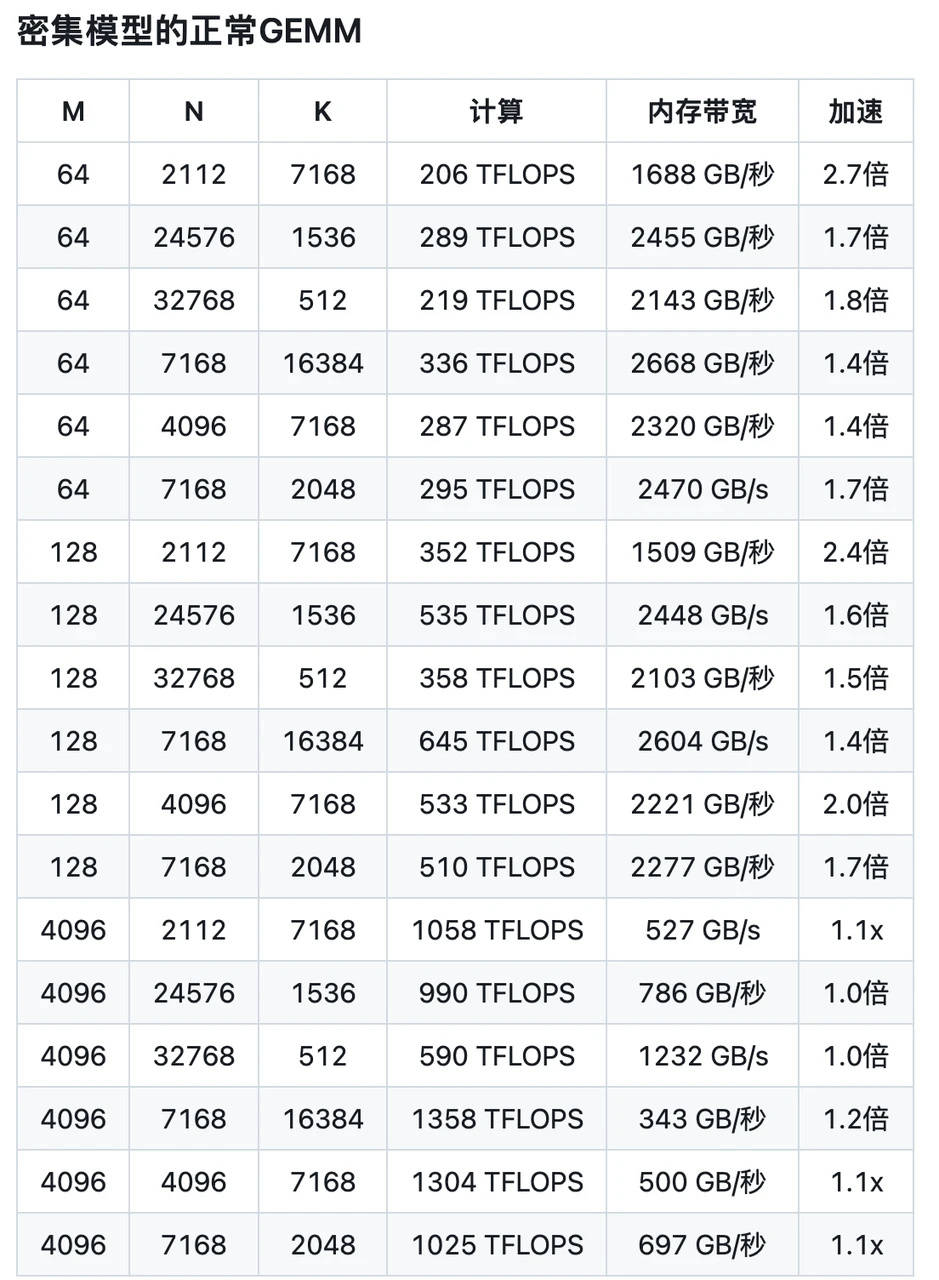
DeepSeek團隊表示,DeepGEMM的性能表現(xiàn)甚至能夠超越英偉達、AMD等專家專門調優(yōu)的庫。在與英偉達CUTLASS 3.6的對比測試中,DeepGEMM的速度提升了2.7倍。這一數(shù)據(jù)無疑為DeepSeek在AI性能優(yōu)化領域的領先地位增添了有力佐證。
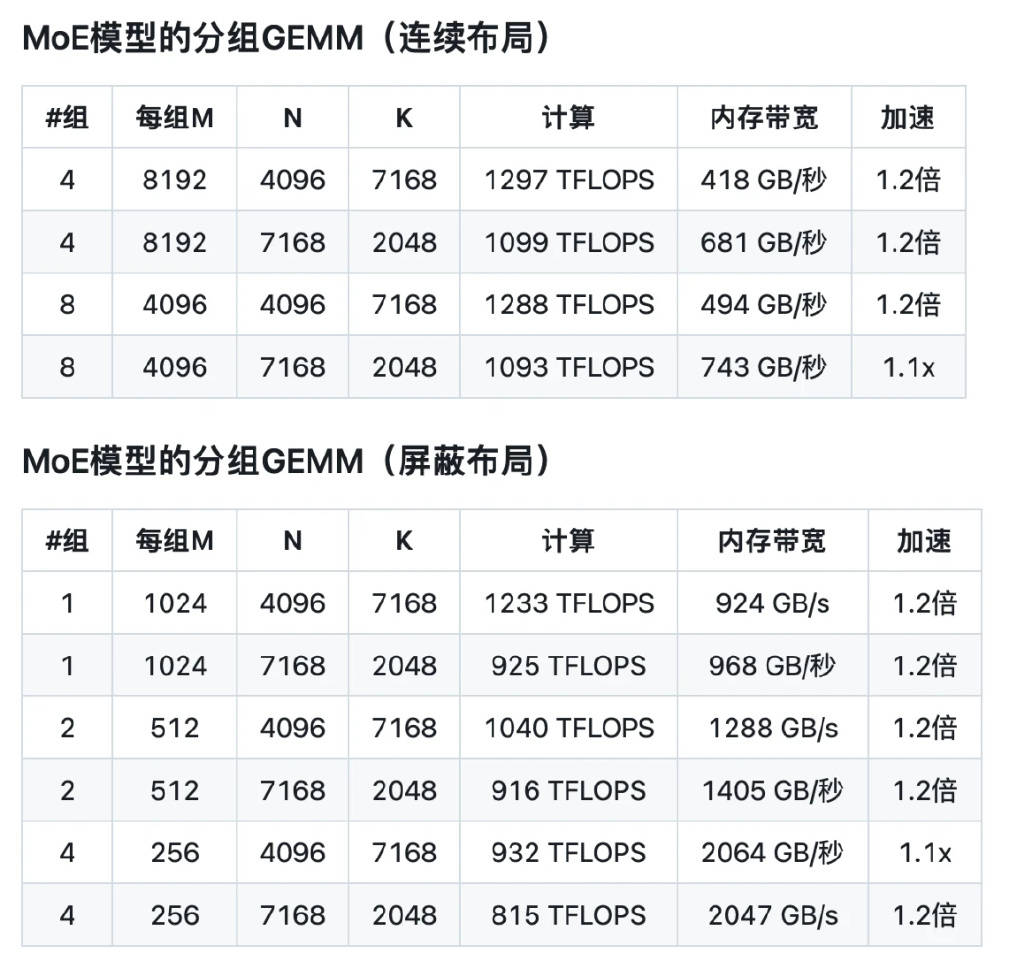
在密集模型檔和專家混合模型MoE的測試中,DeepGEMM均展現(xiàn)出了卓越的性能。密集模型檔測試中,DeepGEMM的表現(xiàn)讓英偉達內部人員也感到難以置信,他們難以想象僅憑幾百行代碼便能實現(xiàn)如此出色的性能優(yōu)化。而在MoE測試中,DeepGEMM的整體性能更是硬核無比,數(shù)據(jù)令人矚目。
盡管DeepGEMM在某些情況下可能表現(xiàn)不佳,但DeepSeek團隊仍誠邀所有開發(fā)者共同參與改進。他們堅信,通過開源和社區(qū)的力量,DeepGEMM將不斷完善并成為AI性能優(yōu)化領域的重要基石。
DeepSeek的開源理念不僅為開發(fā)者提供了便捷高效的工具,更打破了AI領域的閉源壁壘。在AI技術日新月異的今天,開源已成為推動技術發(fā)展的重要力量。DeepSeek的這一舉動無疑為整個AI社區(qū)樹立了榜樣,讓我們共同期待DeepSeek在未來能夠帶來更多創(chuàng)新性的開源項目。