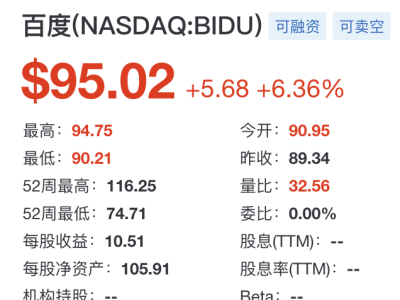
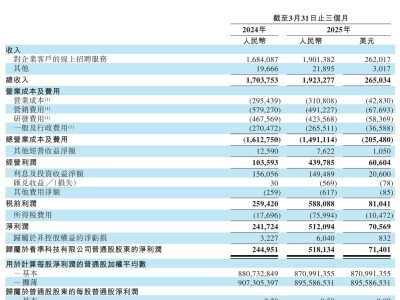
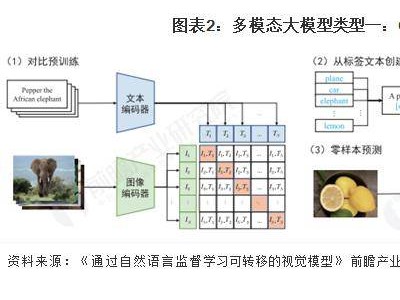
近期,科技巨頭meta與頂尖學府斯坦福大學攜手合作,推出了一款名為Apollo的全新AI模型系列,這一突破性的進展顯著提升了機器對視頻內容的理解能力。
盡管近年來人工智能在圖像和文本處理領域取得了長足的進步,但讓機器真正“看懂”視頻內容依然是一項極為復雜的挑戰。視頻中所蘊含的動態信息豐富且多變,這對人工智能的處理能力提出了極高的要求,不僅需要強大的計算能力作為支撐,更需要在算法設計上實現創新。
為了應對這一挑戰,Apollo模型采用了創新的雙組件設計。其中一個組件專注于處理視頻中的每一幀圖像,而另一個組件則負責追蹤對象和場景隨時間的變化。這一設計使得Apollo能夠更準確地捕捉視頻中的動態信息,從而提升對視頻內容的理解。

在模型訓練方面,meta與斯坦福大學的研究團隊也進行了深入的探索。他們發現,訓練方法的選擇對于模型性能的提升至關重要。因此,Apollo模型采用了分階段訓練的策略,通過按順序激活模型的不同部分,實現了比一次性訓練所有部分更好的效果。

研究團隊還優化了數據組合的比例,發現當文本數據占比在10%至14%之間,且其余部分略微偏向視頻內容時,能夠最好地平衡語言理解和視頻處理能力。這一發現為Apollo模型在實際應用中的表現提供了有力的支持。

Apollo模型在不同規模上都展現出了出色的性能。其中,較小的Apollo-3B模型已經超越了同等規模的Qwen2-VL等模型,而更大的Apollo-7B模型則超過了參數更大的同類模型。這一卓越的表現使得Apollo模型在視頻理解領域具有廣泛的應用前景。
為了更好地推動Apollo模型的發展和應用,meta已經開源了Apollo的代碼和模型權重,并在Hugging Face平臺上提供了公開演示。這一舉措將有助于更多的開發者和研究人員了解和使用Apollo模型,共同推動人工智能技術在視頻理解領域的進步。