
昇思 MindSpore 開源社區將于 2025 年 12 月 25 日在杭州舉辦昇思人工智能框架峰會。本次峰會的昇思人工智能框架技術發展與行業實踐論壇將討論到昇思MindSpore 大模型技術進展與實踐,并將設有昇思 AI for Science(AI4S)專題論壇。本文對 AI4S 團隊開發的 MindSpore Protenix 蛋白質結構預測模型的性能與優化進行了深入解讀,揭示了如何實現該模型的訓練與推理性能的提升。
背景
蛋白質結構預測是現代生命科學的圣杯之一。雖然AlphaFold2等AI工具已實現單體蛋白結構的高精度預測,但整個領域仍面臨兩大核心瓶頸:
第一,預測準確性仍存在系統性盲區。當前模型對蛋白質動態構象、翻譯后修飾狀態、膜蛋白環境以及多鏈復合物組裝等關鍵場景的預測精度嚴重不足。模型在MSA信息稀疏時(如人工設計蛋白、孤兒蛋白)性能會斷崖式下跌,本質上仍是基于進化關聯的“模式外推”而非真正的物理規律學習。
第二,計算復雜性成為應用壁壘。最先進的預測模型需要同時處理數千條同源序列的MSA信息,單次推理就需數十GB顯存和數小時GPU時間。對于需要高通量掃描的工業場景或更大尺度的復合物預測,算力需求呈指數級增長。這使得前沿技術難以轉化為普惠工具,學術實驗室和中小企業常因算力門檻而被排除在創新循環之外。
這兩個問題相互纏繞:要提升對復雜場景的預測精度,往往需要更龐大的模型和更豐富的輸入特征,而這又會進一步推高計算成本,形成難以突破的技術閉環。
昇思 MindSpore 的 AI for Science 方案詳解
昇思 MindSpore 通過軟硬件協同優化及高效的 NPU 計算能力,為行業提供了高性能的自主創新 AI 解決方案,大幅加速蛋白質研究進程并降低計算成本。我們實現了蛋白質結構預測模型 Protenix 的 MindSpore 框架版本,并在昇騰硬件平臺上實現了高性能的訓練和推理。為應對大規模蛋白質結構預測的高計算需求,本項目充分利用 MindSpore 框架的計算圖優化能力與昇騰處理器的硬件優勢,在完全繼承了模型推理精度的同時,又顯著提升了模型性能。
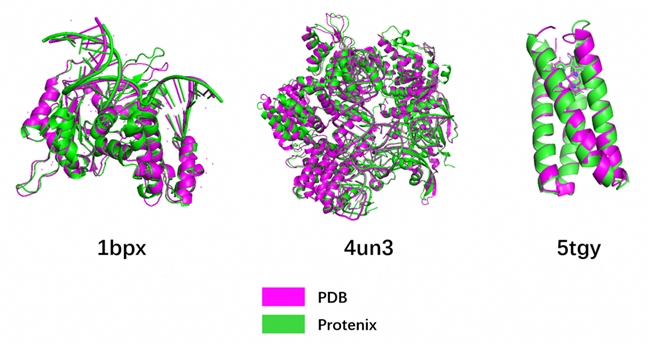
圖1 MindSpore Protenix蛋白質結構預測模型的推理效果
在本文所描述的調優策略下,模型在昇騰A2 64G 單卡上可達到 768 的最大訓練長度,并且最大單卡推理長度超過 3000;以下是相應的具體訓推時間:


2.1 模型訓練優化
重計算(Recompute)優化
在深度模型訓練中,顯存占用通常可分為靜態顯存(Static Memory)與動態顯存(Dynamic Memory)兩個部分。對于 Protenix(AF3 類結構模型) 這類高度依賴幾何結構建模的網絡而言,其瓶頸并非權重規模,而是激活值數量極大、計算路徑復雜、依賴大量三元(i,j,k)結構相關中間張量。通過在前向傳播階段不保存部分激活值,而是在反向傳播需要梯度時重新執行對應的前向計算,即可顯著降低顯存占用。
PyTorch 版本 Protenix 中已經大量使用了重計算來緩解激活膨脹的問題。然而受限于硬件顯存容量限制、模型關鍵結構適配不足,以及考慮到 MindSpore 對動態 shape 的靜態優化與 PyTorch 有一定差異后,我們在 MindSpore 版本中對重計算策略做了更細粒度的優化。
如下圖紅框處所示,a 為未優化前顯存占用曲線,可以看到在紅框處達到峰值。通過分析可以確定此處位置用于計算 smooth_lddt_loss,因此將這個部分單獨進行重計算后就得到了下圖的結果,此處峰值由 55G 下降到 20G 以內。
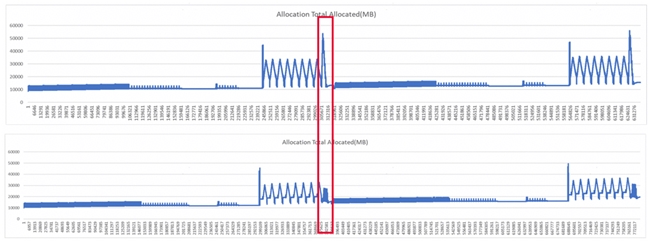
針對性重計算設計
在 MindSpore 實現中,我們分別對核心模塊進行了獨立的重計算包裝,以精確控制激活緩存范圍并最大化釋放顯存。首先是針對 Triangle Attention 的重計算,Triangle Attention 在 AF3 / Protenix 中是最重要的結構依賴模塊之一,其 Q/K/V 計算與 pair-wise 三元交互的復雜度為 O(N^3) ,隨著序列的增長會產生大量中間激活,在昇騰平臺上,由于當前暫時缺乏對等的 fused kernel(如 FlashAttention-like kernel),Triangle Attention 的激活會占用更大量的顯存。因此針對一個 PairFormer Layer 中的兩個 Triangle Attention 分別進行重計算。
其次我們對 Triangle Multiplication 進行重計算,因為 Triangle Multiplication 涉及大量 (i,j,k) 維度重排與張量廣播,且其激活值規模更大。
最后是 smooth_lddt_loss 計算的重計算(大規模 cdist),smooth_lDDT loss 中一項關鍵計算為 pairwise distance(cdist),其生成的距離矩陣為 O(L2 × d),其中L為原子數量,這與 TriangleAttention 等對應的殘基數量不同,原子數量通常比殘基數大一個數量級,因此對長序列顯存壓力極大,我們為 loss 中的該部分單獨加入了重計算,使其在反向不需要保留巨大 distance matrix。
實際顯存收益
在未開啟上述重計算策略時:
? 64GB 顯存僅能訓練長度 64 的序列。
? 動態顯存峰值約為20152 MB。
啟用重計算后:
? 顯存峰值下降到7025 MB,下降超 60%。
? 最長可支持訓練長度提升到 768 tokens。
這一優化是 Protenix MindSpore 版本能夠在昇騰A2 平臺上成功支持長序列訓練的關鍵技術點之一。
2.2 模型推理優化
在這部分工作中,我們基于對模型性能的分析,逐一找到時間、內存方面的性能瓶頸并予以優化。
Profiling 數據與分析
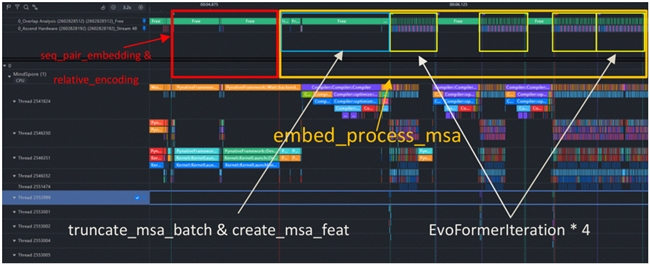
MindSpore 支持用戶使用 Profiler 類對模型的性能進行采集,所獲得的 Profiling 數據記錄了詳細的算子時間線,也包括了算子的顯存占用信息。Profiling 數據可以通過 MindInsight 工具進行可視化分析,可以查看詳細的算子時間線,以及流之間的調用關系。我們可以精確計算出每個模塊的位置及其耗時,并據此來確定這些模塊是否需要進一步的優化。例如,下圖展示了我們對推理過程中 PairFormer 模塊的定位與拆解,為后續的時間、內存的分析提供了框架與引導:
Unfold 算子重構
通過模型運行時打印算子運行時長占比,發現 Im2col 占總運行時長最高,高達 70.73%,故需要分析并消減該算子的調用。
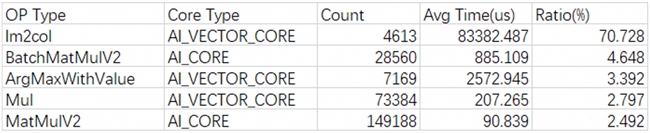
定位后可確定為調用 mindspore.ops.unfold 算子引入問題。根據原本 PyTorch 代碼邏輯,此處實際使用 torch.Tensor.unfold,其實際與 torch.nn.functional.unfold 行為不同,差異如下:
? Tensor.unfold:返回原始張量的一個視圖,該視圖包含在指定維度上從張量中提取的所有大小為 size 的切片。
? nn.functional.unfold:把 4-D 圖像 (N,C,H,W) 的每個 kernel_size 平面窗拉成一列,輸出“二維矩陣”,方便后面用矩陣乘法代替卷積。本質是 im2col 操作,為 im2col 的別名 api。
而 MindSpore 中,Tensor.unfold 與 ms.nn.functional.unfold 實現相同,實際調用為 im2col,因此造成實現差異。故此處整改方案為,使用 MindSpore 實 現 Tensor.unfold 與 torch.Tensor.unfold 相同功能函數進行替換。等價實現后,端到端推理性能提升1倍。后續 MindSpore 實現 Tensor.unfold 算子后可進一步優化顯存占用以提升性能。
融合算子的開發與調優
由于 SelfAttention 的顯存開銷與蛋白質序列長度強相關,且當前對該模塊的優化并不完全親和生物學場景,因此我們選擇開發融合算子 EvoformerAttention。對此,我們實施了以下關鍵改進:
? UB 內存布局重構:消除內存碎片,提升 UB 利用率;
? 消除流同步算子:重構計算流水線,將串行內存拷貝轉為并行異步操作;
? 稀疏掩碼優化:去除 drop_mask 在 UB 中的顯存占用;
? 動態 tiling 調整:基于 UB 剩余容量自適應調整分塊大小,顯著降低循環開銷;以上四個改進總體時間性能提升約 6.5%;
? API 優化:將傳統的 Level 1 API 配合顯式循環的模式,重構為 Level 0 API 的批量處理接口,單步優化后時間性能提升約 5%。
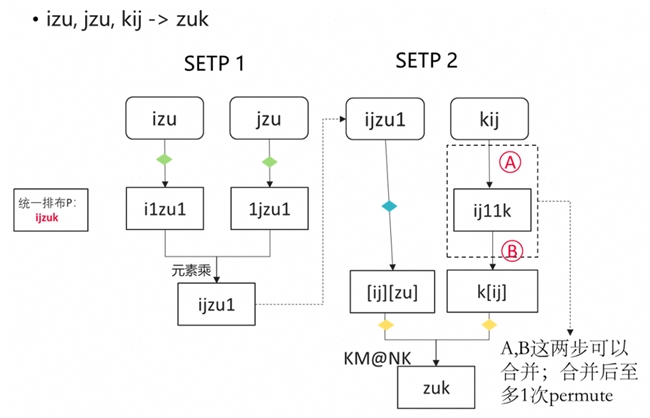
此外,Protenix 中使用了大量的張量計算,其實現方式均為 Einsum(Einstein Summation,愛因斯坦求和約定),因此該算子對模型整體的性能影響較大。Einsum 中規定的張量縮并運算滿足下標表達式

Einsum 高效實現在邏輯上離不開對下標的重排列(permute)。但 permute 操作的時間復雜度是 O(N),我們可以通過優化下標排布,減少或消除顯式的 permute 操作,來進一步提升 Einsum 的算子性能。具體操作包括:
? 放棄不必要的 permute 操作,邏輯上改為對下標循環的重排布,并通過 reshape 操作合并下標,以實現批量操作;可將時間復雜度降到O(1);
? 使用 Mindspore 接口:ops.MatMul(transpose_a=False, transpose_b=False),該接口適配了最低兩維轉置的情況,可以替代符合這種情況下的 permute 操作。
尋找并解決內存瓶頸
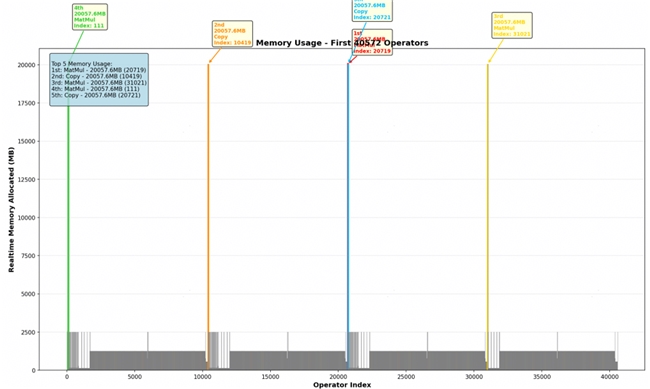
經過此前的優化后,Protenix 模型的 MindSpore 實現版本在單張 A2上的推理極限大致為包含 2000 個殘基的蛋白質序列,也即推理長度的極限只有 2k。通過分析 2k 長度序列推理的 Profiling 數據、調查模型前期出現的若干個算子,我們發現在模型在 PairFormer 階段存在大量的內存瓶頸:
通過對算子的定位我們可以將內存峰值出現的時間與四次 EvoFormer Iteration 相吻合,最終定位出內存瓶頸為該循環中的 outer_product_mean 計算。 該模塊主要承擔張量的縮并計算(愛因斯坦求和操作) 和一些線性變換,而內存瓶頸正是發生在外積計算當中:
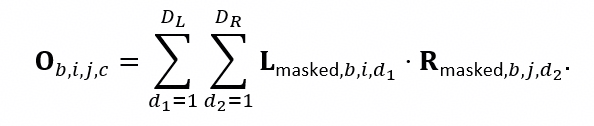
對求和的左側部分進行分塊操作,并調整合適的分塊尺寸(chunk_size),成功降低了內存的峰值。我們后續又定位到其他可能導致內存溢出的位置,分別是:
? 位于PairFormer 階段的 msa_attention,msa_transition 和 triangle_multiplication 計算;
? 位于Diffusion 階段的 transition_block 計算;
? 位于Confidence 階段的 ConfidenceHead 和 GridSelfAttention 計算。
關于分塊操作對時間、內存以及算法精度上的影響,通過理論推導與實驗驗證,我們得到以下結論:
? 我們總是避開了 LayerNorm,Softmax 等非線性操作所涉及的維度,因此分塊不會影響最終推理的精度;
? 整體而言,分塊尺寸與計算時間呈負相關關系,因此可在內存容許的情況下,盡量增大分塊尺寸;下圖展示了 msa_attention 和 GridSelfAttention 在不同分塊下的計算時間;

使用以上策略,我們打通了單張 A2 上的 3k 長度序列推理,成功提高了模型的推理極限。
2.3 jit 裝飾器與靜態圖編譯
MindSpore 與 PyTorch 的核心差異之一在于:
* PyTorch(Eager Mode)采用運行時逐算子調度,算子粒度小、靈活但存在較高 launch 開銷;
* MindSpore 支持通過 **`jit` 裝飾器** 將部分模塊提前編譯為靜態圖(Graph),在執行時以 **大算子形式一次性下發**,極大減少算子調度成本。
在 Protenix 的 MindSpore 復現中,我們主要對 Transformer 模塊進行了 JIT 編譯以提升推理與訓練效率。這主要是由于 Protenix 的 Transformer 層結構 較為規則,輸入維度(hidden size、head_dim、num_heads)均為固定值,適合編譯為計算圖。在 Diffusion 采樣過程中,每步都需要調用 Transformer,共200次,但僅第一次需要編譯,后續可以直接復用。以序列長度 109 的蛋白質 5tgy 在 Atlas A2 的端到端推理性能為例(Diffusion 200 steps):
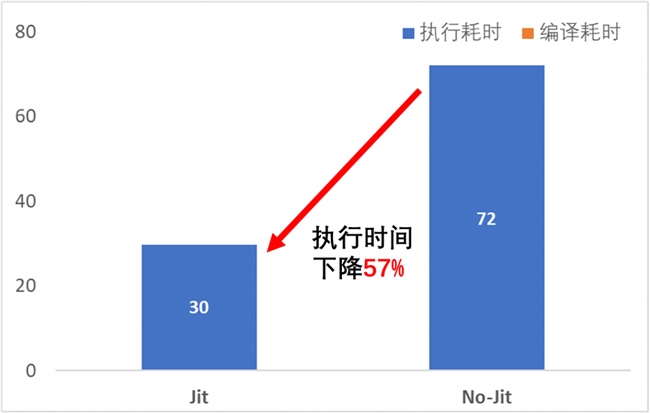
? JIT 編譯耗時大約30 s;
? 運行平穩后耗時約41 s;
? 非 JIT 模式下的推理耗時為72 s;
? JIT 模式下端到端加速比達到57%;
總結
我們成功將蛋白質結構預測模型 Protenix 從 PyTorch 遷移至 MindSpore 框架,并在昇騰 A2 平臺上實現了高性能訓推。針對訓練顯存瓶頸,我們設計了細粒度的重計算策略,對 Triangle Attention、Triangle Multiplication 等模塊進行針對性優化,將動態顯存峰值降低 60% 以上,支持 768 長度序列訓練。推理優化方面,通過重構 unfold 算子消除冗余 im2col 操作,開發 EvoformerAttention 融合算子,優化 Einsum 實現減少數據移動,并采用分塊策略突破outer_product_mean 等模塊的內存瓶頸,以及 JIT 編譯加速等,將推理長度從 2k 擴展至 3k 以上。我們驗證了自主創新計算平臺在前沿蛋白質預測任務中的高效性與可行性,為復雜科學計算模型向 MindSpore 生態遷移提供了實踐范例。
在蛋白質領域,昇思 AI4S 團隊通過算法與自主創新算力的深度協同,使實驗室級的前沿AI工具,成為生物醫藥產業可規模部署的基礎設施。昇思 AI4S 團隊聚焦于打造面向科學發現的專用 AI 框架,致力于構建科學計算與人工智能融合的新型基礎設施。團隊支撐范圍涵蓋了生物信息、地球物理、能源、電磁仿真、計算數學和材料化學等多個領域,未來將進一步打造開源生態并深化基礎設施的建造。昇思社區的 AI4S 開源代碼倉庫可見 https://atomgit.com/mindspore-lab/mindscience.
本次在杭州舉辦的昇思人工智能框架峰會,將會邀請思想領袖、專家學者、企業領軍人物及明星開發者等產學研用代表,共探技術發展趨勢、分享創新成果與實踐經驗。歡迎各界精英共赴前沿之約,攜手打造開放、協同、可持續的人工智能框架新生態!












