

1980年代,卡內基梅隆大學的機器人專家漢斯·莫拉維克(Hans Moravec)提出人工智能領域的一個悖論:讓計算機在邏輯推理、下棋等高級智力活動中達到甚至超越人類水平,相對容易;但要讓它具備孩童那樣的感知、運動和常識認知能力,卻難于登天。
這個悖論的核心在于:對機器而言,真正的困難在于“理解”物理世界并與物理世界進行直覺式的交互。四十余年后,莫拉維克的觀點,也投射在了智能駕駛的漫長征途上。
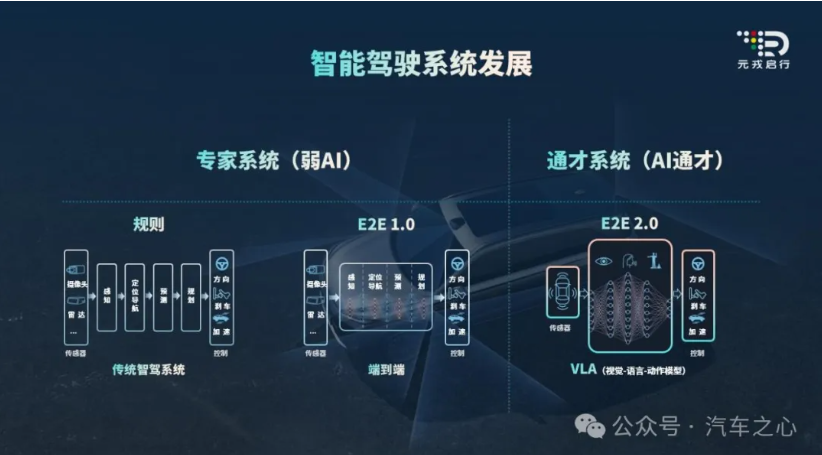
如果現在你跟智駕從業者深聊,會發現一個微妙的變化:幾年前,從業者們還在為傳感器的配置、特定場景的覆蓋率等討論不停;而今天,話題焦點又多了一個更具體的模型結構——VLA(視覺-語言-行動模型)。為什么?
一、智駕的終極體驗,是“像人一樣決策”
我們知道,要實現高階智能駕駛,最大的挑戰之一就在于:真實物理世界的復雜性和不確定性。比如,如何理解一個交警招手動作的復雜意圖?如何判斷一個滾向路邊的足球背后是否會沖出一個孩子?它要求AI不僅要識別物體,更要理解場景、預測意圖并進行復雜的因果推理。為何如此困難?
元戎啟行創始人兼CEO周光,這位擁有物理學背景的AI博士,在前陣子和我們交流時一語道破其中的關鍵。他將駕駛行為劃分為兩個層次:一個是“Move like human”(像人一樣行動),另一個是“Decision like human”(像人一樣決策)。

周光認為,早期的AI決策模型,更擅長處理“條件反射式”的駕駛行為,比如跟車、車道保持、簡單避障等,這些可以被歸納為“Move like human”(像人一樣行動),但這只能解決95%常見的駕駛問題。
但決定智能駕駛安全性和體驗感上限的,恰恰是那些需要推理和預判的長尾場景,也就是圈內常說的Corner Case。他舉了一個直觀例子:“前方兩三百米外有施工,人類老司機會立刻觀察后視鏡,提前變道。但(早期的)智駕系統,可能是開到近處,識別出錐筒、水馬這些障礙物時才做出反應,往往帶來突兀和不舒適的駕乘體驗。”
要解決這個長尾問題,系統必須具備周光所強調的“推理駕駛”(Inferential Driving)能力,這要求系統能夠基于對物理世界規律的“理解”,進行復雜的因果推理和未來預測。
如果無法實現“Decision like human”,系統就可能停留在“高級的輔助駕駛”階段,難以邁向L4乃至更高級別,無法讓人類駕駛員真正放手。智能駕駛的本質,是一個需要理解并作用于真實物理世界的“物理AI”(Physical AI)命題。
要跨越這“最后一公里”,行業亟需一種能夠賦予機器“認知”和“推理”能力的全新范式。這正是VLA這一模型結構,迅速成為當下行業新共識的根本原因。
二、VLA邁向推理駕駛
VLA將視覺(Vision)、語言(Language,代表認知和推理)和動作(Action)融合在一個統一框架內。這種融合帶來了能力層級的質變,超越了簡單的功能疊加。
“從舊架構變成GPT架構,這是一個根本性的變化。”周光反復強調。在他看來,過去的技術迭代(包括BEV等),都只是CNN框架下的“小版本更新”,而VLA才真正開啟了智能駕駛的“大版本升級”,因為它讓系統開始逼近“物理AI”的理想形態。
這種對技術本質的洞察,讓元戎啟行在技術路線上做到知行合一,堅信VLA是實現高階智能駕駛的最優解。“要是不上VLA,我覺得是不可能到L5的。”周光判斷,“VLA讓業界真正看到了實現L5級完全自動駕駛的希望,未來的發展路徑將緊跟大模型技術的演進。”
這家公司早在2019年剛創立不久,就完成了名為“全融合”的技術架構(即早期的BEV鳥瞰圖技術)。到了2020年,便全力投入“無圖”研發,讓系統直接從攝像頭等傳感器獲取的“原始數據”中學習,實時感知和理解物理世界。
到了2022年,周光和團隊的預判得到了初步驗證。他告訴我們,當時團隊已經能通過算法,實時生成道路的拓撲結構圖,雖然還不完美,但已經能清晰識別出路口和轉向關系。這表示“無圖”技術路線被成功跑通,為后續研發奠定了基礎。
VLA帶來的,是用戶體驗上可感知的“老司機感”,這種實實在在的體驗變革,遠勝于冰冷的參數:比如在復雜的城市路口,系統能預判可能出現的“鬼探頭”,提前做出柔和的決策,而非急剎車;在人車混流的狹窄街道,系統能理解交通參與者的“意圖”,進行更靈活的博弈,而不是死板地等待;面對臨時施工或異形障礙物,系統能基于對物理世界的基本理解進行推理,做出合理應對。
這種從“輔助人”向“理解人”乃至“超越人”的進化,也有業界的權威觀點支撐。阿里巴巴集團首席執行官吳泳銘此前在公開演講中指出,通往超級人工智能(ASI)的關鍵瓶頸在于“真實世界的數據”和“自主學習”。他強調:“只有讓AI與真實世界持續互動,獲取更全面、更真實、更實時的數據,才能更好的理解和模擬世界,發現超越人類認知的深層規律。”
一句題外話,我們在寫作之余回溯了周光早年的學術研究,發現他早在德州大學達拉斯分校攻讀博士期間,就提出“去中心化自穩定算法”和“群體協作智能體”模型,探討如何通過局部通信與自組織機制,讓分布式系統在無中心控制下實現穩定協同。這種“由局部交互涌現全局智能”的邏輯,與VLA的視覺、語言、行動三模態的協同推理架構,在思想上已高度契合。
三、VLA 為何需要一座“算力電站”?
然而,為汽車裝上VLA這個強大的“物理AI大腦”,難度巨大。它顛覆了傳統的研發模式,帶來三個“指數級”增長的挑戰,讓智駕公司必須重塑自己。
挑戰一:數據處理的“量級之變”。VLA模型吃的不是“二手”的高精地圖數據,而是物理世界最原始、最鮮活的多模態數據——海量的圖像、視頻、傳感器信號。處理這些數據,對數據處理的吞吐量和效率提出了前所未有的要求。
挑戰二:模型訓練的“范式之變”。訓練VLA模型,就像培養一個天才。不能從零教起,而是采用“知識蒸餾”技術:先用一個擁有千億參數的云端“教師模型”(基座大模型)進行預訓練,再將它的智慧“蒸餾”到車端僅有幾十億參數的“學生模型”上。這個過程,對算力集群的規模、穩定性和調度能力要求極高。
挑戰三:研發效率的“成本之變”。“早些年幾百張卡就能開個小作坊。”周光感慨,“但在VLA時代,幾千張卡是起步,萬卡是入場券。”研發成本結構也從過去“人力占97%,算力占3%”的勞動密集型,轉向“人力與算力一半一半”的資本密集型。
阿里云智能AI汽車行業線銷售總監黃晨,向我們揭示了一個殘酷的現實:“一臺GPU智算服務器,它每一分鐘的成本都可以核算出來。你如果只用了70%,那么30%空跑的時間就是損失掉的真金白銀。”
面對這些挑戰,自建算力中心已非最優解。建設和運維一個“超萬卡集群”,其工程復雜度、能耗和成本都是天文數字。智駕公司最明智的選擇,是接入一個穩定、高效、且懂AI的“算力電網”。
這正是元戎啟行與阿里云的合作進入深水區的原因。他們需要的不是簡單的算力租賃,而是一個能解決VLA時代全鏈路挑戰的合作伙伴。

四、超級AI云的全棧解法
具體而言,阿里云提供的“超級AI云”,是一套從IaaS(基礎設施)、PaaS(平臺工具)到MaaS(模型服務)的全棧式解決方案,精準解決其在VLA路上可能遇到的痛點,從而帶來極致的效率優化。
第一重:以極致的工程能力,構筑穩定高效的算力基石(IaaS層)。
要解決“萬卡集群甚至超萬卡集群”的穩定性問題和通信效率瓶頸,無疑需要久經考驗的系統工程能力。元戎啟行的算力需求,主要由阿里云PAI-靈駿智算服務承載,PAI-靈駿的核心價值在于,通過自研的高性能網絡及智能調度算法,能將大規模集群的AI算力利用率提升超過95%。對于“每一分鐘都是錢”的智駕研發而言,這意味著巨大的成本節約和時間縮短。
VLA訓練中,海量小文件的并發訪問,對存儲系統是極大考驗。對此,阿里云的分布式文件系統CPFS就派上用場,它提供超高并發的多機讀取能力,為萬卡集群提供了數據的“飽和投喂”,確保元戎VLA模型訓練極致高效。
此外,VLA大模型的訓練也是一場圍繞數據的精密接力賽:對元戎啟行而言,百PB級的原始感知數據在深圳匯集、清洗和標注,最終在阿里云烏蘭察布智算集群完成模型迭代。面對該問題,阿里云的云企業網CEN構建了一張覆蓋全國的“算力一張網”,可實現數據和算力的靈活調度。同時,阿里云的全棧安全防護體系,可確保元戎啟行在云端訓練過程中的數據安全。
這些堅實的基礎設施,共同構成了元戎啟行在VLA時代加速奔跑的底氣。
第二重:以獨有的工具鏈,加速數據處理與模型迭代(PaaS層)。
說完了數據訓練,那么說到數據處理,其效率也直接決定了模型訓練的速度,如何高效完成海量多模態數據的清洗、標注和預處理,是模型訓練的重要一步。
在數據處理方面,阿里云自研的分布式計算框架Maxframe,日均可完成數十萬級數據包處理,生成數百萬Clips和數億訓練樣本,相比開源框架性能提升40%以上。同時,結合智能數據開發治理平臺DataWorks,可實現百萬級任務統一開發調度與元數據追溯,高效支撐VLA模型海量多模態數據訓練。這些工具鏈的高效協同,為VLA模型訓練提供了充足且高質量的“燃料”。
接下來在模型訓練階段,迭代速度決定了競爭優勢。阿里云專為智駕領域定制“加速包”PAI-TurboX,在數據層、計算層、系統層深度優化。阿里云計算平臺事業部負責人汪軍華介紹,TurboX能在多個主流模型上將訓練時間縮短50%以上——這意味著元戎的模型迭代周期直接減半,能夠更快將新技術能力應用到產品中。
第三重:以開源開放的生態,提供創新的戰略縱深(MaaS層)。
如上文所提,VLA模型的構建并非從零開始,它需要強大的基座模型進行知識蒸餾和調優。在這一點上,阿里云的開源開放戰略,為元戎啟行提供了助力。
通義千問(Qwen)系列模型,作為全球第一的開源模型矩陣(根據Huggingface開源大模型榜單Open LLM Leaderboard),它目前全球下載量超6億次,衍生模型超17萬個,為行業提供了堅實基座。周光對此高度認可:“元戎啟行經常用通義大模型去做一些蒸餾,通義開源挺好的。”這種開放性,讓元戎啟行得以站在基座模型的肩膀上,更高效優化自己的車端模型。
同時,它支持廠商基于開源能力做深度自研,這一點至關重要。這使得元戎啟行能夠將寶貴的研發資源,投入到智駕垂類知識的積累和創新上,而不是重復造輪子。
從IaaS的工程能力,到PaaS的工具鏈,再到MaaS的開源開放生態,阿里云提供的“超級AI云”全棧能力,構筑了其在智駕訓練領域的重要地位。正如阿里云智能集團公共云事業部AI汽車行業總經理李強在一次公開演講中提到,超過60%中國智能輔助駕駛的AI算力來自阿里云。這足以證明,阿里云已成為智駕訓練中那朵好用的云。
五、選擇對的伙伴,駛向更遠的路
誠然,強大的技術基建,最終要轉化為商業成果和產業引領。
在商業策略上,許多智駕公司廣撒網、服務多個品牌車型(多SKU),而作為全棧智能駕駛解決方案提供商元戎啟行,再次展現了與其技術路線一致的“專注”。
周光進一步指出,有的智駕公司SKU特別多,但月銷可能只有幾百臺;元戎啟行專注于“大單品”策略——集中資源與車企深度合作,打造爆款車型。在他看來,只有深度合作,才能打磨出極致的產品體驗。“你越是做的散,做的雜,你這個產品越難。”
這種“少而精”的策略背后,是對自身技術研發效率的絕對自信。而這份自信,很大程度上來源于其選擇了一個能提供長期價值、深刻理解AI、并具備開放生態的云合作伙伴。
當然,智駕的商業化過程中,成本控制也至關重要。如今智駕已成標配,而非溢價項。黃晨告訴我們:“車上有智駕,不一定讓你多賣1萬塊,但如果沒有,一定不被接受。”
換句話說,當智駕成為“標配”而非“溢價項”,Tier 1供應商的利潤空間被持續擠壓。這樣一來,選擇云服務商,早已超越了單純的資源采購,更上升為一項關乎核心競爭力的戰略決策。因為云端基礎設施的技術深度與工程效率,直接決定了算法迭代的速度和質量,進而影響最終產品的市場競爭力。
對元戎啟行而言,與阿里云合作的核心價值,在于通過阿里云全棧式的技術能力(包括高效的基礎設施、長期積累的技術價值、以及開源開放的生態),將每一分算力的技術價值發揮到極致。這正是其構筑自身技術壁壘、實現商業正循環的底氣所在。
對于所有致力于在物理AI時代取得突破的智能駕駛參與者而言,元戎啟行的實踐極具參考價值:要跨越智能駕駛的“最后一公里”,需要擁抱VLA;而要高效地訓練VLA,需要選擇一朵像阿里云這樣具備全棧能力、能夠提供長期價值陪伴、且開源開放的“超級AI云”。
因為在新世界里,走得快需要好的技術。而走得遠,則需要好的伙伴。











