近期,華為技術有限公司在人工智能領域的創新再添新章。據天眼查信息顯示,該公司于7月18日公布了一項名為“一種模型訓練方法、數據生成方法及相關設備”的專利。
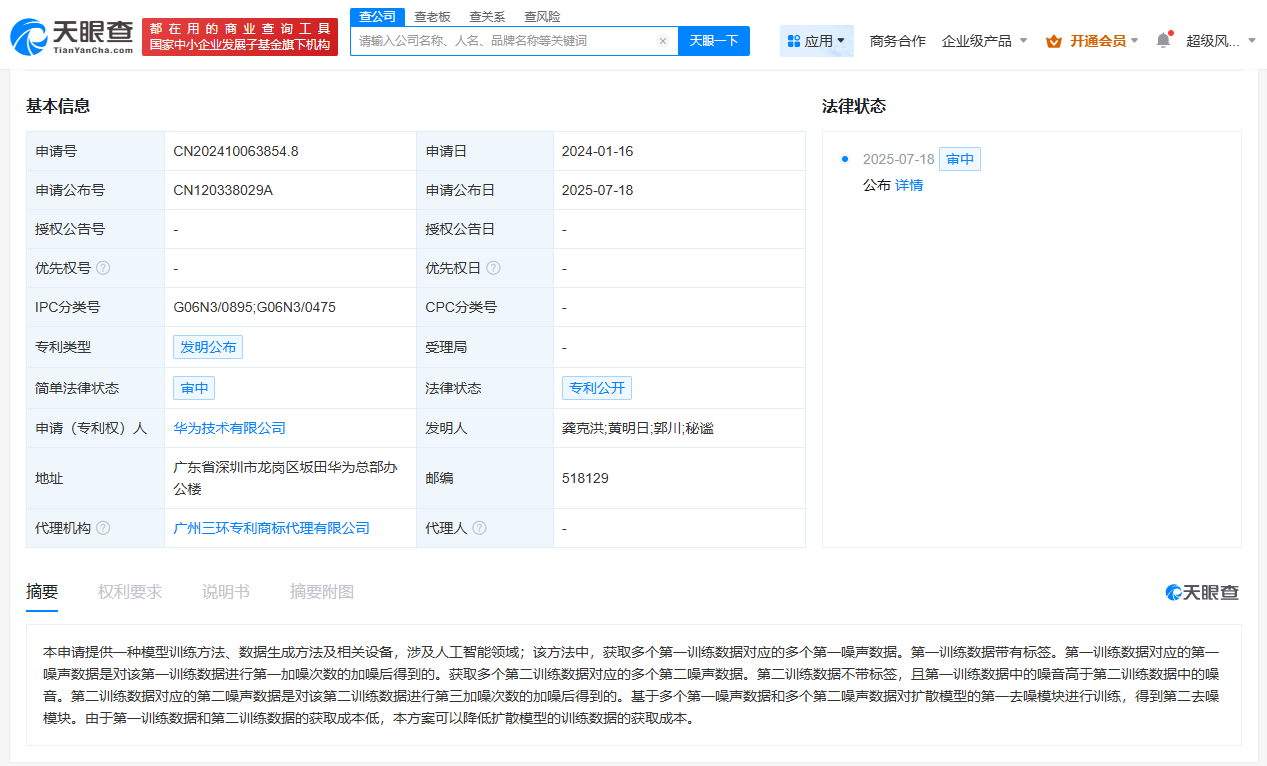
該專利聚焦于如何通過創新的手段降低擴散模型訓練數據的獲取成本。具體而言,該方法巧妙地運用了帶有標簽的第一訓練數據和不帶標簽的第二訓練數據,以及它們對應的噪聲數據。
在第一階段,系統獲取多個第一訓練數據,這些數據均帶有明確的標簽,并通過對它們進行特定次數的加噪處理,生成對應的第一噪聲數據。緊接著,系統又獲取多個第二訓練數據,這些數據不帶有標簽,但它們的噪聲水平相較于第一訓練數據要低。同樣地,第二訓練數據也經過加噪處理,生成了對應的第二噪聲數據。
值得注意的是,這兩種訓練數據及其噪聲數據的獲取成本都相對較低,這為后續的模型訓練奠定了堅實的基礎。基于這些噪聲數據,系統對擴散模型的第一去噪模塊進行了訓練,并最終得到了優化后的第二去噪模塊。
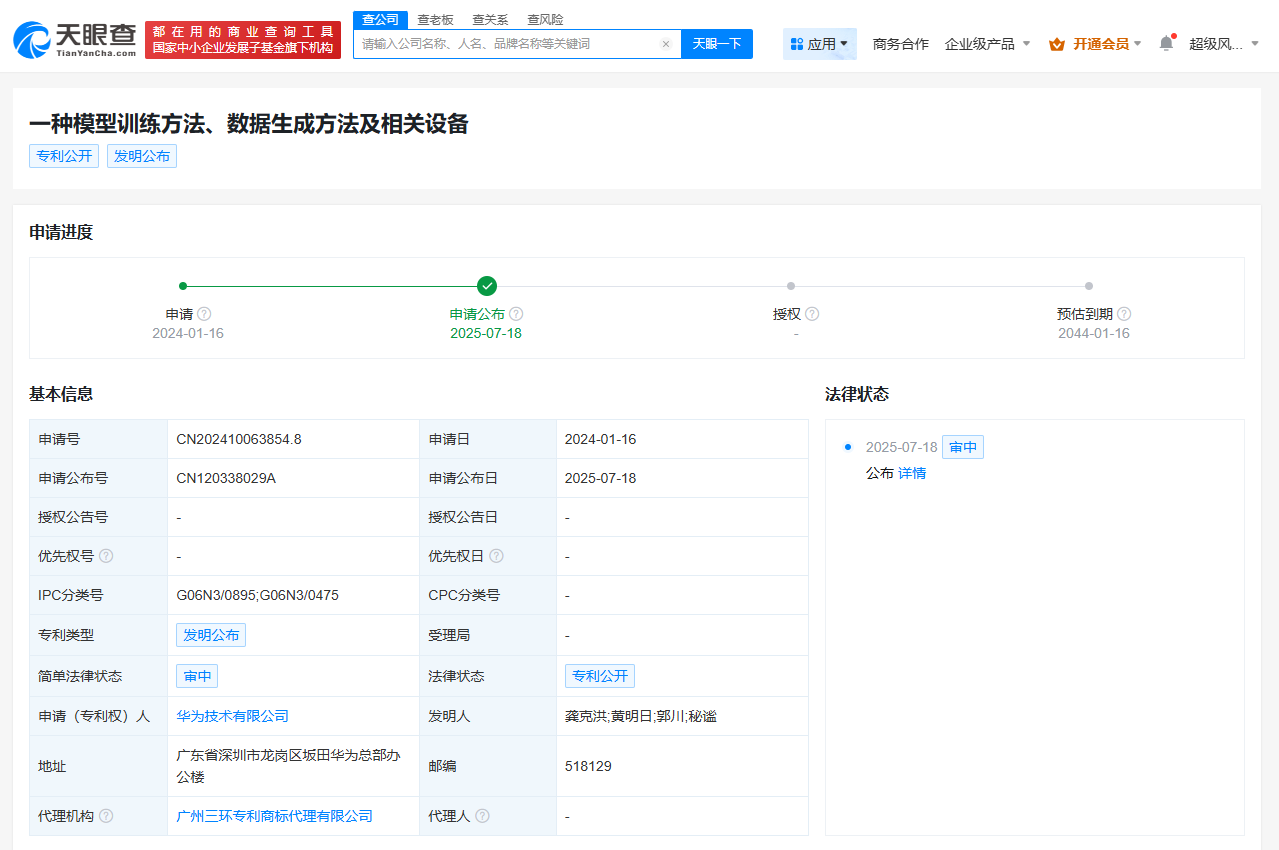
據天眼查進一步的信息揭示,這種創新的訓練方法不僅簡化了數據獲取流程,還顯著提高了模型訓練的效率。通過利用不同噪聲水平的訓練數據,華為成功地降低了對高質量、高成本標注數據的依賴,從而推動了人工智能技術的進一步發展。
該方法還為其他領域的數據處理和模型訓練提供了新的思路。它證明了在人工智能領域,通過巧妙的數據處理和算法設計,可以在不犧牲性能的前提下,有效降低數據獲取和處理的成本。
華為此次公布的專利,無疑再次彰顯了其在人工智能領域的深厚實力和持續創新能力。隨著人工智能技術的不斷發展,我們有理由相信,華為將繼續引領行業潮流,推動人工智能技術向更高水平邁進。