在當今科技飛速發展的時代,多模態大模型正成為人工智能技術探索的新前沿。這一領域匯聚了眾多行業巨頭與創新企業,如阿里巴巴、百度、騰訊等,它們不僅在各自的業務領域內深耕細作,更在多模態大模型的研發上展開了激烈的角逐。
多模態大模型的探索之路并非一帆風順,它要求在不同的模態領域實現技術突破,從視覺到音頻,從圖像到視頻,再到3D模型,每一步都充滿了挑戰。然而,正是這些挑戰激發了產業的創新活力。理想中的“Any-to-Any”大模型,如Google的Gemini、Codi-2等,雖然仍處于探索階段,但它們為未來的技術發展指明了方向。
在圖像模型領域,產業界已經積累了豐富的經驗。從CLIP、Stable Diffusion到GAN等模型,再到Midjourney、DALL · E等應用,圖像的理解和生成技術已經取得了顯著的進步。如今,產業界正積極探索將Transformer大模型引入圖像相關任務,試圖建立統一視覺大模型,并與大語言模型進行更緊密的融合,如GLIP、SAM、GPT-V等成果,正是這一趨勢的體現。
視頻模型作為圖像模型的延伸,也取得了令人矚目的進展。由于視頻本質上是由多幀圖像組成,因此圖像生成模型的技術可以遷移到視頻生成。近年來,VideoLDM、W.A.L.T.等模型的出現,標志著視頻生成技術邁出了重要的一步。特別是Sora模型,它在視頻生成領域首次呈現出“智能涌現”的跡象,為未來的技術發展提供了新的可能。
在3D模型領域,產業界同樣在積極探索。雖然相比圖像和視頻生成,3D模型生成技術還處于早期發展階段,但GAN、自回歸、Diffusion、VAE等模型在3D模型生成任務中的擴展已經取得了初步成果。3D數據表征、數據集和生成模型的不斷完善,為3D應用的發展提供了堅實的基礎。
音頻模型方面,Transformer大模型的引入成功推動了語音技術的進一步發展。從Whisper large-v3到VALL-E等模型的出現,語音技術的泛化能力得到了顯著提升。從單一語種到多語種和方言,從人聲到自然聲音和音樂,從簡單語音識別或合成到零樣本學習和多任務集成,語音技術的應用范圍不斷擴大。
Omni模型作為音頻模型的一個重要成果,它利用neural audio codec對音頻進行編碼以實現音頻合成。通過embedding和adapter對文本和聲波進行編碼,再通過Omni模型進行合成和預測音頻的token,最后通過擴散模型進行訓練和解碼器合成音頻,這一過程展示了音頻技術的最新進展。
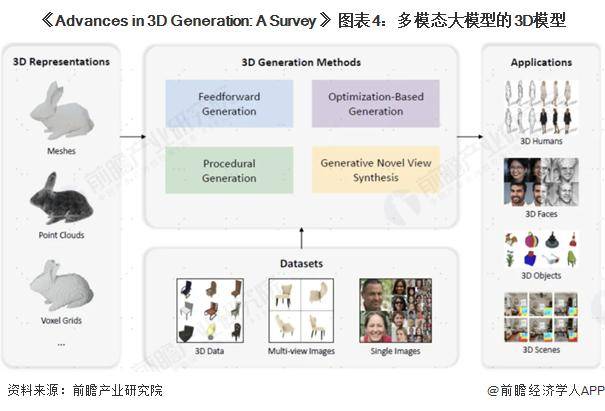

多模態大模型的探索正在逐步取得進展,從圖像到視頻,再到3D模型和音頻模型,每一步都充滿了創新與挑戰。未來,隨著技術的不斷發展,多模態大模型將在更多領域發揮重要作用,為人類社會帶來更多的便利和驚喜。