DeepSeek R1模型近期迎來了其發(fā)展歷程中的又一重要里程碑,全新版本DeepSeek-R1-0528正式亮相。此次迭代通過深度優(yōu)化訓(xùn)練流程,顯著增強(qiáng)了模型的邏輯推理與深度思考能力,使其在多個測試場景中均展現(xiàn)出了前所未有的高水平表現(xiàn)。
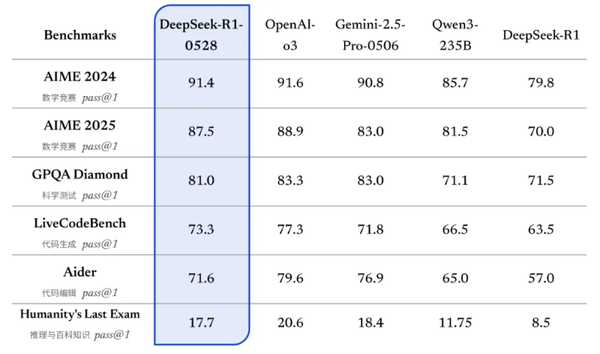
在深度思考領(lǐng)域,DeepSeek-R1-0528基于2024年底發(fā)布的DeepSeek V3 Base模型進(jìn)行了全面升級,借助更為強(qiáng)大的計算能力,實現(xiàn)了性能上的飛躍。在數(shù)學(xué)解題、編程挑戰(zhàn)以及通用邏輯推理等測試中,新模型均取得了國內(nèi)領(lǐng)先、接近國際頂尖水平的成績,如與o3和Gemini-2.5-Pro等模型比肩。尤其在備受矚目的AIME 2025競賽中,DeepSeek-R1-0528的準(zhǔn)確率從舊版的70%大幅提升至87.5%,這一顯著進(jìn)步得益于其更為細(xì)致和深入的解題策略,平均每題思考所使用的tokens數(shù)量從12K增加到了23K。
除了深度思考能力的顯著增強(qiáng),DeepSeek-R1-0528在解決“幻覺”問題上也取得了重要突破。在文本改寫、內(nèi)容總結(jié)、閱讀理解等多個應(yīng)用場景中,新模型的幻覺率降低了近半,提供了更加準(zhǔn)確和可靠的結(jié)果。在創(chuàng)意寫作領(lǐng)域,DeepSeek-R1-0528針對議論文、小說、散文等多種文體進(jìn)行了細(xì)致優(yōu)化,能夠生成篇幅更長、結(jié)構(gòu)更為完整且風(fēng)格貼近人類偏好的長篇作品。
DeepSeek-R1-0528還新增了工具調(diào)用功能,雖然在思考過程中暫不支持工具調(diào)用,但在Tau-Bench測評中展現(xiàn)出了與OpenAI o1-high相當(dāng)?shù)膶嵙ΑM瑫r,新模型在前端代碼生成、角色扮演等場景下的表現(xiàn)也有所提升,進(jìn)一步拓寬了其應(yīng)用場景。
在API方面,DeepSeek-R1-0528也進(jìn)行了同步更新。雖然接口與調(diào)用方式保持不變,但新增了對Function Calling和JsonOutput的支持,為用戶提供了更為靈活和便捷的使用體驗。官方還對max_tokens參數(shù)進(jìn)行了重新定義,用于限制模型單次輸出的總長度,包括其思考過程,從而幫助用戶更好地控制輸出內(nèi)容。

此次DeepSeek-R1-0528的升級不僅展現(xiàn)了DeepSeek團(tuán)隊在AI技術(shù)研發(fā)上的深厚實力,也為廣大用戶帶來了更為高效、智能和可靠的使用體驗。隨著技術(shù)的不斷進(jìn)步,我們有理由相信,DeepSeek模型將在未來繼續(xù)引領(lǐng)AI領(lǐng)域的發(fā)展潮流。