在科技界的萬(wàn)眾矚目下,阿里巴巴正式推出了其最新的通義千問(wèn)模型Qwen3(簡(jiǎn)稱千問(wèn)3),該模型一經(jīng)發(fā)布便迅速登頂全球最強(qiáng)開(kāi)源模型的寶座。這一壯舉發(fā)生在4月29日凌晨,阿里巴巴宣布開(kāi)源這一新一代模型,標(biāo)志著人工智能領(lǐng)域的一次重大突破。
千問(wèn)3的旗艦?zāi)P蚎wen3-235B-A22B,盡管參數(shù)量?jī)H為DeepSeek-R1的三分之一,總參數(shù)量達(dá)到235B,但激活時(shí)僅需22B,實(shí)現(xiàn)了成本的大幅下降。更為驚人的是,其性能全面超越了R1、OpenAI-o1等全球頂尖模型,成功登頂。這一成就不僅彰顯了阿里巴巴在人工智能領(lǐng)域的深厚積累,更為全球開(kāi)源模型樹(shù)立了新的標(biāo)桿。
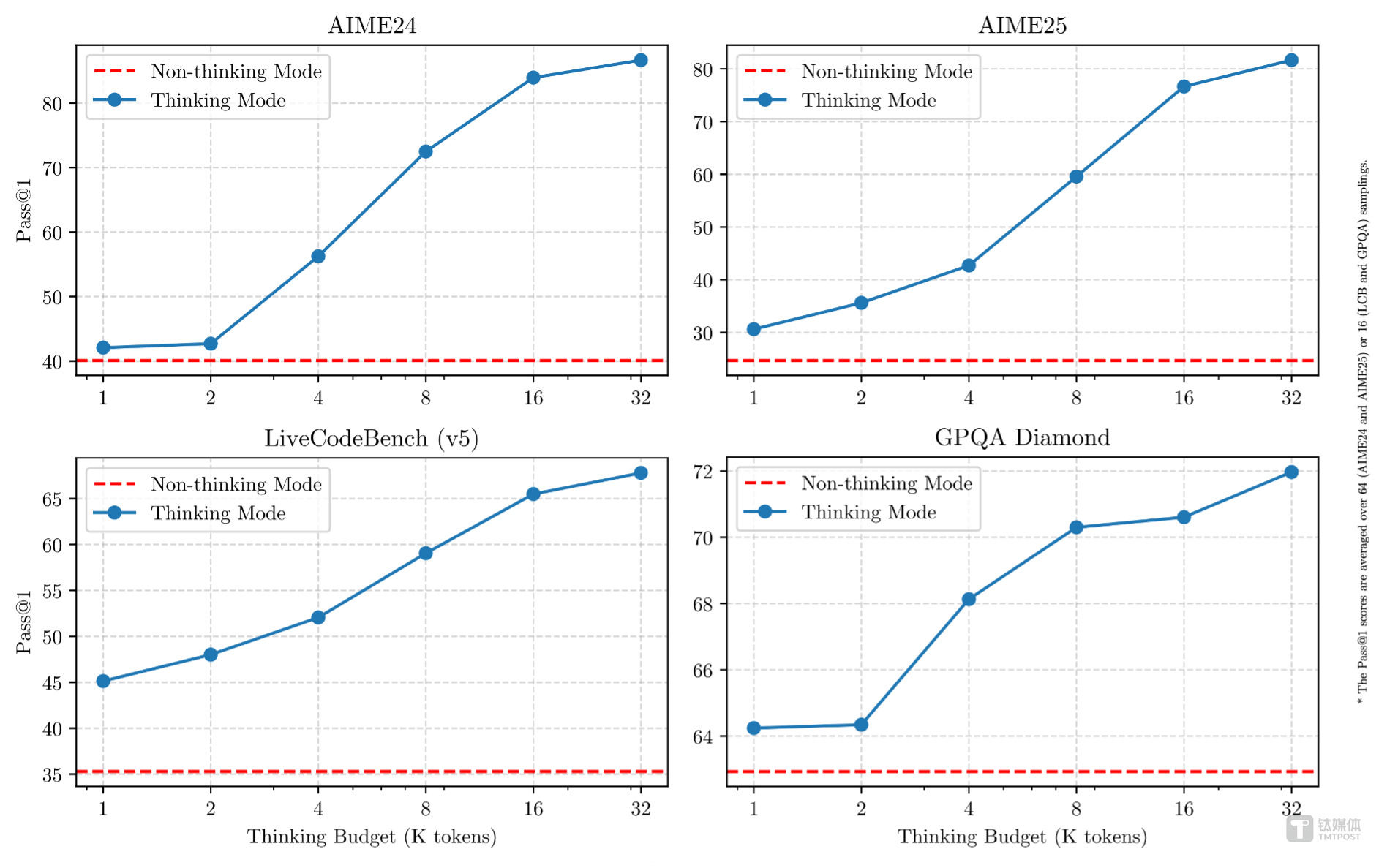
千問(wèn)3的預(yù)訓(xùn)練數(shù)據(jù)量高達(dá)36T,經(jīng)過(guò)多輪強(qiáng)化學(xué)習(xí)的后訓(xùn)練階段,將快思考模式和慢思考模式無(wú)縫整合。這一創(chuàng)新使得千問(wèn)3在推理、指令遵循、工具調(diào)用、多語(yǔ)言能力等方面均實(shí)現(xiàn)了大幅提升,創(chuàng)下了所有國(guó)產(chǎn)模型及全球開(kāi)源模型的性能新高。千問(wèn)3的推出,無(wú)疑為人工智能領(lǐng)域注入了新的活力。
此次發(fā)布的千問(wèn)3系列模型共計(jì)八款,包括兩款30B、235B的MoE模型,以及0.6B、1.7B、4B、8B、14B、32B等六款密集模型。每一款模型都在同尺寸的開(kāi)源模型中取得了最佳性能(SOTA),展現(xiàn)了千問(wèn)3系列模型的強(qiáng)大實(shí)力。其中,30B參數(shù)的MoE模型實(shí)現(xiàn)了模型性能杠桿的10倍以上提升,僅需激活3B就能媲美上代Qwen2.5-32B模型的性能;而32B版本的千問(wèn)3模型,更是能夠跨級(jí)超越Qwen2.5-72B的性能。
4月成為了大模型集中發(fā)布的一個(gè)月。除了千問(wèn)3之外,OpenAI發(fā)布了GPT-4.1 o3、o4 mini系列模型,谷歌推出了Gemini 2.5 Flash Preview混合推理模型,豆包也公布了1.5·深度思考模型。業(yè)內(nèi)還傳出DeepSeek R2模型即將發(fā)布的消息,但千問(wèn)3的“先發(fā)制人”無(wú)疑搶占了大模型“平民化”的先機(jī)。
千問(wèn)3作為國(guó)內(nèi)首個(gè)混合推理思考模型,支持兩種思考模式:慢思考模式和快思考模式。在慢思考模式下,模型會(huì)逐步推理,給出深思熟慮的答案,適合復(fù)雜問(wèn)題;而在快思考模式下,模型則提供快速、即時(shí)的響應(yīng),適用于簡(jiǎn)單問(wèn)題。這一創(chuàng)新使得千問(wèn)3能夠根據(jù)不同需求進(jìn)行不同程度的思考,大大節(jié)省了算力消耗。

在性能大幅提升的同時(shí),千問(wèn)3的部署成本也大幅下降。僅需4張H20即可部署千問(wèn)3滿血版,顯存占用僅為性能相近模型的三分之一。千問(wèn)3模型還支持119種語(yǔ)言和方言,滿足了全球用戶的需求。目前,這些模型均在Apache 2.0許可下開(kāi)源,并已在Hugging Face、ModelScope和Kaggle等平臺(tái)上開(kāi)放使用。
千問(wèn)3不僅在性能和成本上取得了顯著優(yōu)勢(shì),還在智能體Agent和大模型應(yīng)用落地方面做出了積極探索。在評(píng)估模型Agent能力的BFCL評(píng)測(cè)中,千問(wèn)3創(chuàng)下了70.8的新高,超越了Gemini2.5-Pro、OpenAI-o1等頂尖模型。同時(shí),千問(wèn)3原生支持MCP協(xié)議,并具備強(qiáng)大的工具調(diào)用能力,將大大降低編碼復(fù)雜性,實(shí)現(xiàn)高效的手機(jī)及電腦Agent操作等任務(wù)。
在預(yù)訓(xùn)練方面,Qwen3的數(shù)據(jù)集相比Qwen2.5有了顯著擴(kuò)展。Qwen3使用了約36萬(wàn)億個(gè)token的數(shù)據(jù)進(jìn)行預(yù)訓(xùn)練,幾乎是Qwen2.5的兩倍。為了構(gòu)建這一龐大的數(shù)據(jù)集,千問(wèn)團(tuán)隊(duì)不僅從網(wǎng)絡(luò)上收集數(shù)據(jù),還從PDF文檔中提取信息,并利用專家模型合成數(shù)學(xué)和代碼數(shù)據(jù)。預(yù)訓(xùn)練過(guò)程分為三個(gè)階段,逐步提升了模型的語(yǔ)言技能和通用知識(shí)。
在后訓(xùn)練方面,千問(wèn)團(tuán)隊(duì)實(shí)施了一個(gè)四階段的訓(xùn)練流程,旨在開(kāi)發(fā)同時(shí)具備思考推理和快速響應(yīng)能力的混合模型。這一流程包括長(zhǎng)思維鏈冷啟動(dòng)、長(zhǎng)思維鏈強(qiáng)化學(xué)習(xí)、思維模式融合以及通用強(qiáng)化學(xué)習(xí)。經(jīng)過(guò)這一系列的訓(xùn)練,千問(wèn)3成功實(shí)現(xiàn)了推理和快速響應(yīng)能力的無(wú)縫結(jié)合。
目前,個(gè)人用戶已經(jīng)可以通過(guò)通義APP直接體驗(yàn)千問(wèn)3,夸克也即將全線接入千問(wèn)3。阿里巴巴通義已經(jīng)開(kāi)源了200余個(gè)模型,全球下載量超過(guò)3億次,千問(wèn)衍生模型數(shù)超過(guò)10萬(wàn)個(gè)。這一成就不僅超越了美國(guó)的Llama模型,更使千問(wèn)3成為了全球第一開(kāi)源模型。