英偉達近期震撼發布了Describe Anything 3B(簡稱DAM-3B)這一前沿AI模型,專為解決圖像與視頻中特定區域的精細描述問題而生。該模型在靜態圖像及動態視頻的局部描述領域取得了突破性進展,為相關領域開辟了新的道路。
盡管傳統的視覺-語言模型(VLMs)在生成整體圖像描述方面已相當成熟,但在處理圖像或視頻中特定區域的詳細描述時卻存在明顯短板。特別是在動態視頻中,時間動態變化、遮擋現象以及區域化描述的需求,使得這一任務變得尤為復雜。DAM-3B的推出正是為了攻克這些難題,它允許用戶通過點選、邊界框、涂鴉或掩碼等方式指定目標區域,進而生成精確且貼合上下文的描述性文本。
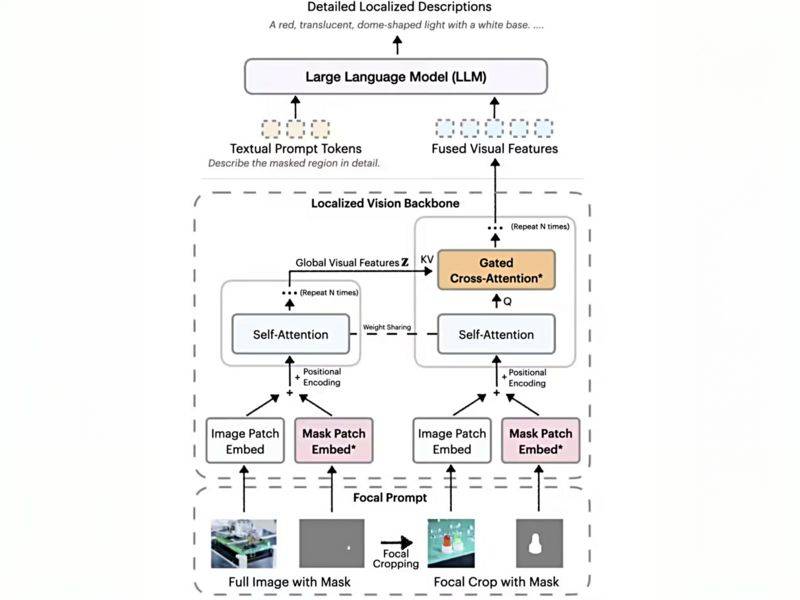
DAM-3B的核心創新在于其“焦點提示”技術。該技術巧妙地將全圖信息與目標區域的高分辨率裁剪圖相結合,既保留了整體背景,又確保了細節信息的真實呈現。這種獨特的融合策略,使得生成的描述更加精確且上下文連貫。
DAM-3B還引入了局部視覺骨干網絡。該網絡通過嵌入圖像和掩碼輸入,運用先進的門控交叉注意力機制,將全局與局部特征有機融合,再傳遞給大語言模型以生成描述。這一設計使得模型能夠更深入地理解目標區域及其與整體圖像之間的關系。
DAM-3B的能力不僅局限于靜態圖像,其衍生版本DAM-3B-Video更是將這一技術擴展至視頻領域。通過逐幀編碼區域掩碼并整合時間信息,DAM-3B-Video即使在面對遮擋或運動的情況下,也能生成準確的描述,為動態視頻的局部描述提供了強有力的解決方案。
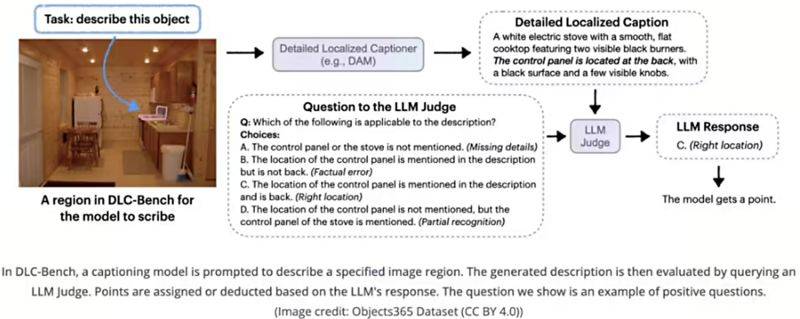
為了克服訓練數據稀缺的難題,英偉達創新性地開發了DLC-SDP半監督數據生成策略。該策略充分利用分割數據集和未標注的網絡圖像,構建了包含150萬局部描述樣本的訓練語料庫。通過自訓練方法不斷優化描述質量,確保了輸出文本的高精確度。同時,英偉達還推出了DLC-Bench評估基準,以屬性級正確性作為衡量描述質量的標準,而非簡單地與參考文本進行對比。

在包括LVIS、Flickr30k Entities等在內的七項基準測試中,DAM-3B展現出了卓越的性能,平均準確率達到67.3%,成功超越了GPT-4和VideoRefer等模型,彰顯了其在圖像和視頻局部描述領域的領先地位。