過去一年,如果把全球云廠商的技術路線攤開來看,會出現一個很有意思的畫面。行業內的兩家老大哥AWS 和 Google,幾乎在同一時間朝著兩個方向用力。
一個方向是向下。
芯片、網絡、系統軟件、調度、基礎設施,被一層一層重新打磨。云廠商已經不滿足于把算力賣出去,而是越來越執著于把底層的控制權握在自己手里。目的其實很樸素,讓推理負載變得穩定、可控,像一套工業設備一樣,能長時間運轉、不掉鏈子、不出幺蛾子。
另一個方向是向上。
模型服務、Agent 能力、開發平臺不斷被收攏、封裝。曾經零零散散的 API 和工具,被重新組織成一條完整的應用生產線。云不再只是原料供應商,而是直接下場,參與 AI 應用從設計到落地的整個過程。
這兩個方向看起來一上一下,實則指向同一個判斷:云已經不再把 AI 當成一種普通負載,而是把它當成正在重塑云自身形態的主業務。當推理成為核心負載,云要解決的問題也隨之升級。不只是夠不夠快,而是能不能長期跑、跑得穩、跑得清楚,出了問題還能追溯、能治理。
ChatGPT 的出現,把這件事猛地往前推了一大步。企業很快發現了一個現實,模型再強,如果做不成應用、進不了流程、管不住風險,價值就會迅速打折。
于是,關注點開始悄然轉移。比起誰的模型更聰明,企業更關心的是誰能把 AI 變成一個可交付、可運營、可治理的系統。也正是在這樣的背景下,越來越多人把 2025 年稱為 Agent 落地元年。并不是因為 Agent 一夜之間變得多么聰明,而是承載 Agent 的平臺、工具和基礎設施,終于開始像一套成熟的生產系統。
當競爭從模型升級為平臺,一個更現實的問題隨之浮出水面:平臺的強弱,究竟該由誰來定義?模型可以上榜單、比分數,但平臺能力涉及的是系統工程、治理機制,以及長期運行的確定性,顯然不是廠商自己喊幾句口號就能說清的。
Forrester 為什么要給 Agent 開發平臺排名很多人第一次看到 Forrester Wave 時,都會下意識把它當成一張廠商排行榜。但如果把視角拉回到企業現場,會發現 Forrester 真正想解決的,其實不是誰更靠前,而是一個更現實的問題:當 AI 開始進入生產系統,企業到底該怎么選平臺。
在 AI 還停留在試驗階段時,企業的采購方式是可以拼裝的。模型單獨買,算力單獨租,向量庫、工具鏈、集成服務各找各的供應商,只要 demo 能跑起來,流程勉強通順,就算階段性成功。但一旦 AI 被放進核心業務鏈路,問題會在極短時間內集中暴露:出了故障很難說清責任歸屬,數據權限在系統之間反復穿透,治理規則各自為政,穩定性和成本曲線也開始失控。
正是從這一刻起,企業的采購邏輯發生了根本變化。相比買能力,他們更想買體系。把數據、模型、推理、Agent 和治理能力統一收攏到一套平臺里,不是為了省事,而是為了確定性——誰負責、怎么管、出了問題能不能追溯和回滾,這些都必須在平臺層面成為默認能力,而不是依賴項目經驗和人工兜底。
Forrester 的問題意識,正是從這里出發的。它評的不是某一個技術點有多先進,而是平臺在真實企業環境里的可用性。換句話說,平臺能不能陪企業把 AI 從能用一路跑到長期可運營。在 Forrester 的評估框架里,數據能力是否扎實、ModelOps 是否覆蓋全生命周期、Agent 能否在治理與安全邊界內進入業務流程,才是決定分數的關鍵。
全棧能力決定Agent場景的「產品能力」如果把 AI 平臺比作一輛要上高速、還要跑長途的車,Forrester 的關注點其實很樸素:油路穩不穩(數據底座)、保養體系全不全(ModelOps 全生命周期)、自動駕駛能不能安全上路(Agent 進入業務流程)、以及剎車和行車記錄儀是不是出廠自帶(治理、審計、可追溯與回滾)。它評的不是某個零件有多炫,而是整車能不能長期、穩定、可運營地跑起來。
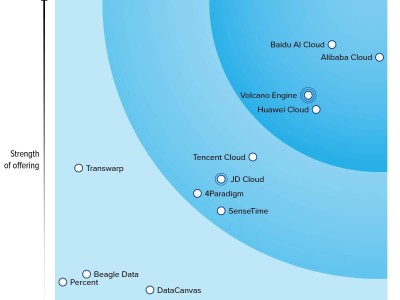
按這套標準,國內格局已經分層得很清楚。Leaders 是全棧車廠:阿里云、百度智能云在右上角,說明既能打也敢投;火山引擎、華為云同樣處在領先象限,但路線更鮮明,一個更偏性能和 Agent 落地效率,一個更偏全棧基礎設施與可控性。
分數進一步把這種差異量化了。在 Current offering 維度上,百度以 4.46 領先,阿里為 4.30,火山 3.82、華為 3.64 緊隨其后。領先者的優勢并不來自某個參數的單點突破,而是整車工程做得更完整、更均衡。
那為什么百度能在這套評估里更靠前?Forrester 給出的線索其實很具體,可以拆解為三條連續的能力鏈路。
第一步,把找資料變成平臺原生能力。報告點名百度把 Search 用在 RAG 和 agentic AI 上,這相當于給企業的知識庫配了一套自帶索引的導航系統,不用每次臨時外掛檢索組件、靠運氣拼效果。更重要的是,報告同時強調百度在數據集成、管道、質量、安全與隱私上的表現,這些看起來不性感,卻決定了企業敢不敢把 RAG/Agent 放進主流程。
第二步,把模型當成長期資產來養。Forrester 對千帆 ModelBuilder 的評價集中在開發、訓練、微調、評估、部署的覆蓋度。意思不只是能做模型,而是能把模型上線后持續管理:版本怎么控、效果怎么評、出了問題怎么回退。平臺把這些動作做成默認項,企業的落地阻力就會小一大截。
第三步,不只搭應用,更要能跑得久。報告認為千帆 AppBuilder 的應用開發特性較完整,并特別指出百度在 platform operations 上整體更強。翻譯過來就是:從可觀測到治理到回滾,系統更像可持續運行的生產設施,而不是上線之后靠人值守。
三步合起來,百度得分靠前的邏輯就很直觀了。知識鏈路更穩、模型生命周期更全、應用運營更可控。這也恰好踩中 Forrester 的核心標準,比的不是某個炫技功能,而是一套能把 AI 長期跑在生產系統里的默認能力。
平臺標準落地后,中國 AI 云正在走向少數解當評估標準從能不能做出效果切換到能不能長期運營,市場就會自動進入下一階段:誰能把 AI 從一次性項目,變成一套可以長期跑、持續交付、出問題能回滾的系統,誰才有資格留在主桌。
中國市場之所以更容易、更快走向收斂,原因并不在于競爭不充分,而在于場景天然更嚴苛。金融、能源、政務、制造等行業對穩定、合規、連續運行的要求接近剛性,AI 一旦進入主流程,就不再是隨時可撤的創新嘗試,而是會直接影響業務安全與運營效率的生產設施。
這個變化也被需求側的數據與招采條款進一步放大。2025 年上半年,中國大模型中標項目數達到 1810 個、金額突破 64 億元,規模不僅超過 2024 全年,也意味著真金白銀正在加速流向核心產業。與此同時,客戶的要價明顯變硬:從租幾張 GPU 卡,變成要一套可信賴、可持續交付的 AI 算力系統。類似“7×24 小時安全運營服務”“99.999% 可用性”這樣的要求,本質上是在把 AI 平臺當作關鍵基礎設施來驗收,而不是把它當作一項新功能來試用。
金融行業的招投標也呈現出同樣的趨勢:2025 年 1–9 月相關中標項目數量與披露金額顯著抬升,說明主戰場正在從“試點”走向“常態化部署”。
阿里云和百度智能云路徑不完全相同,但在關鍵命題上給出了相似答案:強化對底層資源與系統的控制,把 AI 當作需要長期維護的生產系統,把數據、模型、推理、Agent 和治理統一納入平臺調度。這種全棧化不是為了贏一場短跑,而是為了在高要求場景里把長期可用變成默認值。