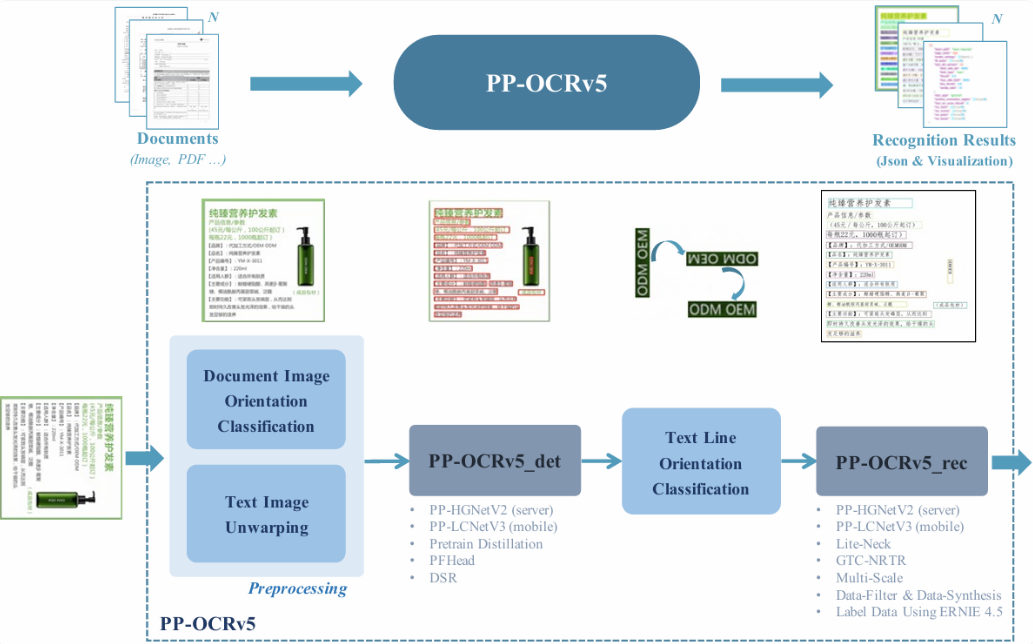
近日,百度在開源社區Hugging Face正式上線了新一代光學字符識別(OCR)技術方案PP-OCRv5。該模型專為解決大型視覺語言模型(VLMs)在文本定位與識別精度上的不足而設計,通過模塊化架構實現了高效輕量的解決方案。
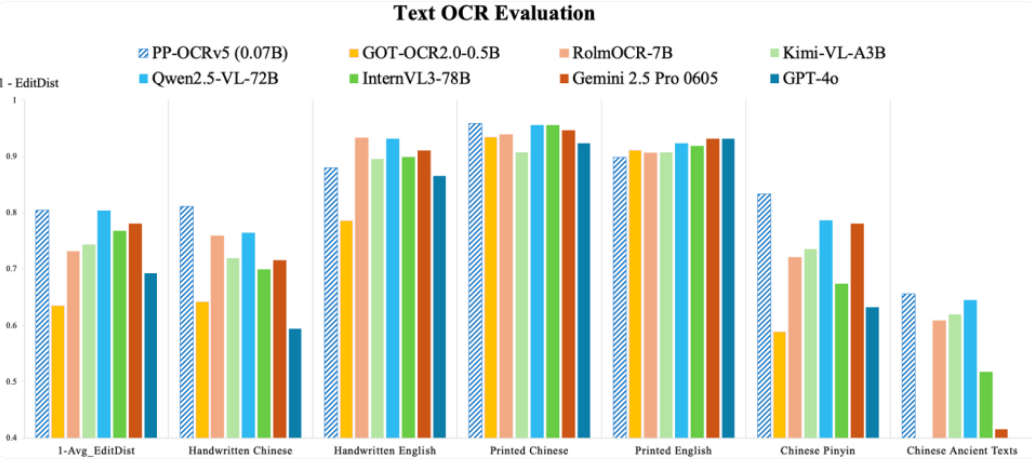
與傳統通用型VLM模型相比,PP-OCRv5采用兩階段處理流程,在保持模型輕量化的同時顯著提升了文本檢測精度。其核心優勢在于精準的文本行邊界框定位能力,可有效處理手寫體、印刷體及拼音文本的識別需求,尤其適用于結構化數據提取等場景。實測數據顯示,該模型移動端版本在英特爾Xeon Gold 6271C處理器上可達每秒370字符的處理速度,參數規模僅0.07B。
在性能對比測試中,PP-OCRv5在中英文、日文及拼音文本的識別任務上全面超越Gemini 2.5 Pro、Qwen2.5-VL等主流VLM模型。其多語言支持體系覆蓋簡體中文、繁體中文、英文、日文四大語系,并具備識別超過40種語言的能力,展現出強大的跨語言處理潛力。
該技術方案由四大核心模塊構成:圖像預處理模塊負責校正圖像畸變與旋轉;文本檢測模塊精準定位文本區域;方向分類模塊確保文本正確對齊;最終識別模塊將字符序列轉換為可讀文本。這種模塊化設計不僅提升了處理效率,更增強了模型對復雜場景的適應能力。
行業專家指出,PP-OCRv5的推出為邊緣計算設備部署高性能OCR技術提供了新思路。其輕量化特性使其特別適用于移動端、物聯網設備等資源受限場景,有望推動文檔數字化、智能客服、無障礙閱讀等領域的創新應用。