7 月 20 日消息,英偉達今日推出了全新推理模型套件 OpenReasoning-Nemotron。該套件包含四個基于 Qwen-2.5 微調的模型,參數規模分別為 1.5B、7B、14B 和 32B,全部源自 6710 億參數的 DeepSeek R1 0528 大模型。通過“蒸餾”這一過程,英偉達成功將這一超大規模模型壓縮成更輕量的推理模型,降低了部署門檻,使得即使在標準游戲電腦上也能進行高級推理實驗,避免了高昂的 GPU 與云計算成本。

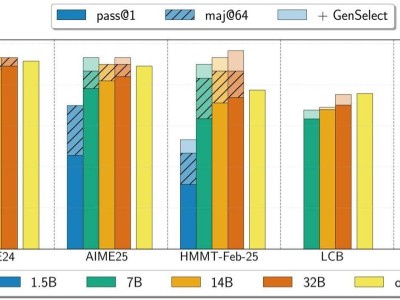
據了解,英偉達此次模型的核心優勢并非在于訓練手段的復雜創新,而是依托強大的數據支撐。公司利用 NeMo Skills 生成了 500 萬個涵蓋數學、科學與編程的解答數據集,并通過純監督學習方式對模型進行微調。經測試,32B 模型在 AIME24 數學競賽中獲得 89.2 分,在 HMMT 2 月賽中達到 73.8 分,甚至最小的 1.5B 模型也分別拿下 55.5 和 31.5 分,展現出良好的推理與解題能力。


英偉達將 OpenReasoning-Nemotron 定位為科研探索的有力工具,四個模型的完整檢查點將在 Hugging Face 開放下載,便于研究人員基于此進行強化學習等進一步實驗,或針對特定任務定制優化。同時,模型支持“GenSelect 模式”,即每個問題可生成多種解答版本,通過篩選最優解來提升準確率。在該模式下,32B 模型在多項數學與編程基準測試中已達到甚至超越 OpenAI o3-high 的表現。
英偉達此次模型訓練全程未引入強化學習,僅采用監督微調,為社區提供了干凈且處于技術前沿的起點,便于未來開展強化學習相關研究。對于擁有高性能游戲 GPU 的玩家及個人開發者而言,這套模型讓本地運行接近業界最先進水平的推理模型成為現實。