自2020年起,尹首一教授前瞻性地瞄準(zhǔn)超高性能大模型訓(xùn)練與推理場景,開展了晶圓級芯片這一前沿技術(shù)路線的探索。以胡楊教授為骨干,團(tuán)隊(duì)提出了晶圓級芯片“計(jì)算架構(gòu)”與“集成架構(gòu)”兩大核心設(shè)計(jì)方法,本次ISCA的三項(xiàng)成果分別面向計(jì)算架構(gòu)問題、集成架構(gòu)問題與大模型推理任務(wù)映射問題開展研究,構(gòu)建了晶圓級芯片“計(jì)算架構(gòu)-集成架構(gòu)-編譯映射”協(xié)同設(shè)計(jì)優(yōu)化方法學(xué),取得了國內(nèi)外學(xué)術(shù)界與工業(yè)界的廣泛認(rèn)可。
在產(chǎn)出高水平學(xué)術(shù)研究成果的基礎(chǔ)上,團(tuán)隊(duì)聯(lián)合清華系知名芯片企業(yè)研發(fā)了可重構(gòu)算力網(wǎng)格芯粒,并聯(lián)合上海人工智能實(shí)驗(yàn)室成功制造出國內(nèi)首臺基于可重構(gòu)AI芯粒的12寸晶圓級芯片驗(yàn)證樣機(jī),驗(yàn)證了在次世代工藝條件下采用晶圓級集成方式趕超先進(jìn)工藝芯片的理論和工程可行性,為解決國內(nèi)芯片“卡脖子”難題提供了兼具引領(lǐng)性和可行性的技術(shù)路線。工程成果已經(jīng)反哺多家產(chǎn)業(yè)界頭部合作伙伴,實(shí)現(xiàn)了產(chǎn)學(xué)研用高效閉環(huán)。
ISCA國際計(jì)算機(jī)體系結(jié)構(gòu)研討會(International Symposium on Computer Architecture)是計(jì)算機(jī)體系結(jié)構(gòu)領(lǐng)域的頂級會議,創(chuàng)辦于1973年,被譽(yù)為“計(jì)算機(jī)體系結(jié)構(gòu)創(chuàng)新的風(fēng)向標(biāo)”,其收錄成果代表了該項(xiàng)研究的國際前沿突破性和全球創(chuàng)新引領(lǐng)性。
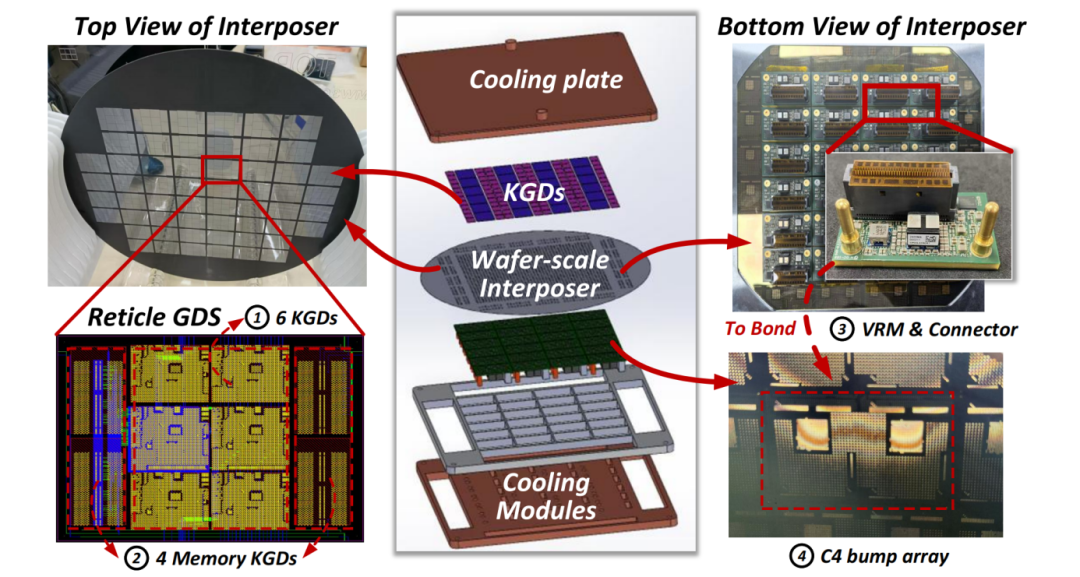
基于可重構(gòu)AI芯粒的晶圓級芯片驗(yàn)證樣機(jī)
重構(gòu)軟硬件系統(tǒng),
晶圓級芯片加碼AI算力
何謂晶圓級芯片?它又為何是AI行業(yè)算力突破的“明日之星”?
晶圓級芯片(Wafer-Scale Chip)是一種顛覆傳統(tǒng)計(jì)算形態(tài)與半導(dǎo)體制造模式的前沿技術(shù)。眾所周知,芯片的算力與芯片內(nèi)部能夠集成的晶體管數(shù)量相關(guān),能夠集成的晶體管數(shù)目越多則芯片的算力越高,而晶體管數(shù)量又由單位面積的晶體管密度和芯片的面積兩個關(guān)鍵的因素來協(xié)同決定。其中前者主要依賴于集成電路的工藝先進(jìn)性,然而在我國目前面臨著嚴(yán)重的“卡脖子”困境。而后者主要受集成電路光刻技術(shù)的制約,在現(xiàn)有工藝條件下只能達(dá)到858平方毫米的面積,這也制約了常規(guī)芯片能夠達(dá)到的總算力上限。
在構(gòu)建更大算力的系統(tǒng)時,常規(guī)芯片傳統(tǒng)的封裝和互連模式使得多個芯片間的互連往往需要經(jīng)過中介層、基板、PCB、線纜、光模塊、交換機(jī)等層層延遲,互連密度也被封裝結(jié)構(gòu)大幅稀釋,嚴(yán)重制約了其性能表現(xiàn)。因此,在追求極致算力與能效時,我們希望能夠構(gòu)建更大的芯片并設(shè)計(jì)更加高效的集成方式。
晶圓級芯片,顧名思義,是設(shè)計(jì)和制造一顆晶圓尺寸(約40000平方毫米)的超大面積芯片,實(shí)現(xiàn)“One Wafer One Chip”。其典型技術(shù)路線是通過在一整片晶圓上制造高密度硅互連基板,再將數(shù)十顆算力芯粒集成到硅晶圓基板上,從而構(gòu)建成一整片晶圓尺寸的算力芯片。
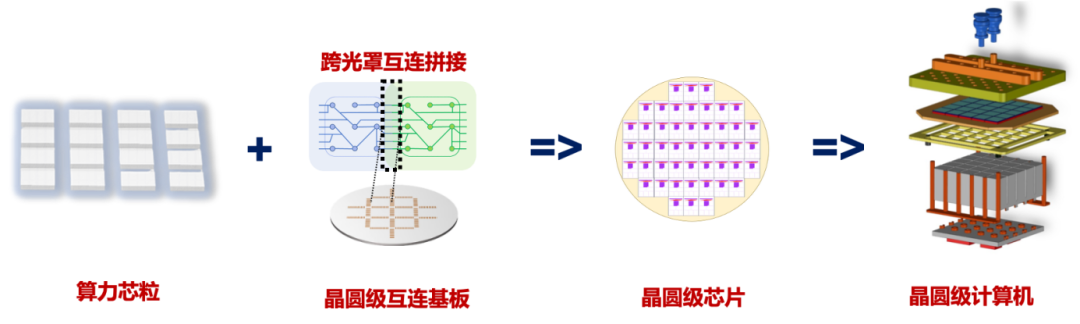
以Chiplet技術(shù)為基礎(chǔ)的晶圓級芯片制造流程
值得注意的是:晶圓級芯片不單純是一塊利用先進(jìn)封裝技術(shù)拼接出來的大芯片,本質(zhì)上是整個智算系統(tǒng)在芯片級實(shí)現(xiàn)的高度集成。不夸張的說,晶圓級芯片就是一款“片上數(shù)據(jù)中心”,涉及計(jì)算、存儲、互連、封裝、供電、散熱、可靠性、機(jī)械結(jié)構(gòu)等多個設(shè)計(jì)因素的高度耦合,在設(shè)計(jì)時需要高度統(tǒng)籌計(jì)算架構(gòu)與集成架構(gòu)的協(xié)同優(yōu)化問題。
我們可以從兩層意義上來解讀晶圓級芯片帶來的優(yōu)勢:1. 如果將整個晶圓看做是一顆大芯片,在搭建具有同等算力的集群時,采用晶圓級芯片方案無疑比常規(guī)芯片方案具有更少的節(jié)點(diǎn)數(shù)目,因此可以獲得更佳的集群擴(kuò)展線性度和性能。2. 更深一層看,晶圓級芯片在算力上可以對標(biāo)一個甚至多個當(dāng)前的多卡算力服務(wù)器或者超節(jié)點(diǎn),同時具有更高的互連密度,更短的互連距離,更大的集成密度,因此可以獲得更高的性能和能效。經(jīng)測算,其單機(jī)柜算力密度能夠達(dá)到現(xiàn)有超節(jié)點(diǎn)方案的2倍以上。可以說,晶圓級芯片是目前為止算力節(jié)點(diǎn)集成密度最高的一種形態(tài)。目前國際上已有美國的Cerebras WSE系列和特斯拉 Dojo系列兩款晶圓級芯片產(chǎn)品。
ISCA 2025論文導(dǎo)讀
晶圓級芯片以超大規(guī)模的單片集成方式,成為支撐下一代人工智能算力的新型芯片架構(gòu)。晶圓級芯片的設(shè)計(jì)、制造和應(yīng)用超越了當(dāng)前“算力芯片-服務(wù)器-超節(jié)點(diǎn)”的常規(guī)范式,亟待突破一系列關(guān)鍵問題。本次的三篇論文從計(jì)算架構(gòu)、集成架構(gòu)、編譯映射角度構(gòu)建了晶圓級芯片的完整體系。
《PD Constraint-aware Physical/Logical Topology Co-Design for Network on Wafer》提出了以互連為中心的晶圓級芯片計(jì)算架構(gòu)(第一作者為團(tuán)隊(duì)博士學(xué)生楊啟澤)。
文中指出,晶圓級芯片計(jì)算架構(gòu)的核心是設(shè)計(jì)和構(gòu)造全晶圓尺度的互連架構(gòu)。在硅互連基板上設(shè)計(jì)片上互連網(wǎng)絡(luò)面臨嚴(yán)格的物理約束,包括有限且相互競爭的硅晶圓面積、不超過50mm的互連長度以及少于3層的金屬布線資源。
本文首次系統(tǒng)性揭示了計(jì)算架構(gòu)中的關(guān)鍵矛盾并提出"Tick-Tock"協(xié)同設(shè)計(jì)框架,將物理拓?fù)渑c邏輯拓?fù)涞膬?yōu)化緊密耦合。本文通過創(chuàng)新性融合Mesh的高集成度與Fat tree高效通信特性,提出Mesh-Switch物理拓?fù)溆?jì)算架構(gòu),并設(shè)計(jì)了physical-design感知的設(shè)計(jì)空間搜索算法,可獲得最優(yōu)物理拓?fù)渑渲谩?/p>
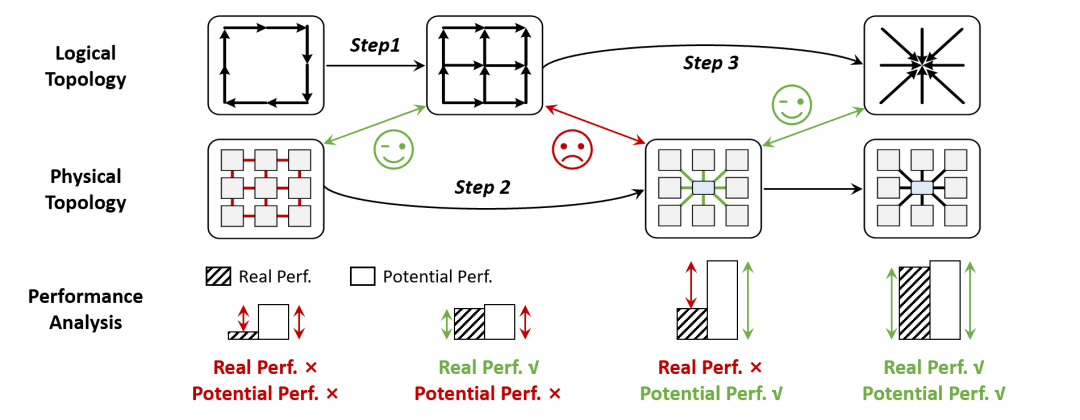
"Tick-Tock"協(xié)同設(shè)計(jì)的晶圓級芯片計(jì)算架構(gòu)
對比當(dāng)前典型晶圓級芯片架構(gòu),本文提出的晶圓級芯片計(jì)算架構(gòu)更有效的利用了物理資源,實(shí)現(xiàn)了更優(yōu)物理拓?fù)湓O(shè)計(jì)。同時,針對物理拓?fù)涮匦栽O(shè)計(jì)雙層次邏輯拓?fù)洌?xì)粒度并行策略以及拓?fù)涓兄牟⑿蟹桨冈O(shè)計(jì),從路由算法、通信流水到并行策略實(shí)現(xiàn)全棧優(yōu)化。實(shí)驗(yàn)結(jié)果表明,該方案在主流大模型訓(xùn)練任務(wù)中對比特斯拉Dojo可實(shí)現(xiàn)2.39倍的吞吐提升。本文突破了現(xiàn)有方案的性能瓶頸,確立物理約束下物理拓?fù)?邏輯拓?fù)?并行方案協(xié)同設(shè)計(jì)的新范式,為晶圓級芯片提供了關(guān)鍵理論基礎(chǔ)與具體方案。《Cramming a Data Center into One Cabinet, a Co-Exploration of Computing and Hardware Architecture of Waferscale Chip》提出了垂直空間協(xié)同設(shè)計(jì)的晶圓級芯片集成架構(gòu)(第一作者為團(tuán)隊(duì)碩士學(xué)生余幸懋)。
晶圓級芯片是一個垂直堆疊的多層結(jié)構(gòu),算力芯粒、存儲芯粒、I/O模組、供電模組、散熱模組等多種異構(gòu)單元集成于互連基板的上下表面垂直空間內(nèi)。例如,特斯拉的Dojo晶圓級芯片系統(tǒng)結(jié)構(gòu)從上到下依次為散熱層、算力芯粒、中介層、基板、供電模組和外部連接器。這些多樣化異構(gòu)資源的高密度集成,面臨異構(gòu)設(shè)計(jì)因素緊耦合、系統(tǒng)性能優(yōu)化難的問題,是晶圓級芯片集成架構(gòu)亟需解決的難題。
本文首次提出以縱向面積約束引導(dǎo)跨物理層協(xié)同優(yōu)化的晶圓級集成架構(gòu)設(shè)計(jì)方法學(xué)。具體而言,本文建立了各物理層的面積模型,利用晶圓級系統(tǒng)內(nèi)跨層的功率依賴模型和信號傳遞關(guān)系,將各物理層的設(shè)計(jì)參數(shù)和指標(biāo)統(tǒng)一變換為縱向面積約束。該方法考慮計(jì)算架構(gòu)和集成架構(gòu)的協(xié)同設(shè)計(jì),實(shí)現(xiàn)了單芯片到整機(jī)的系統(tǒng)級設(shè)計(jì)與優(yōu)化。
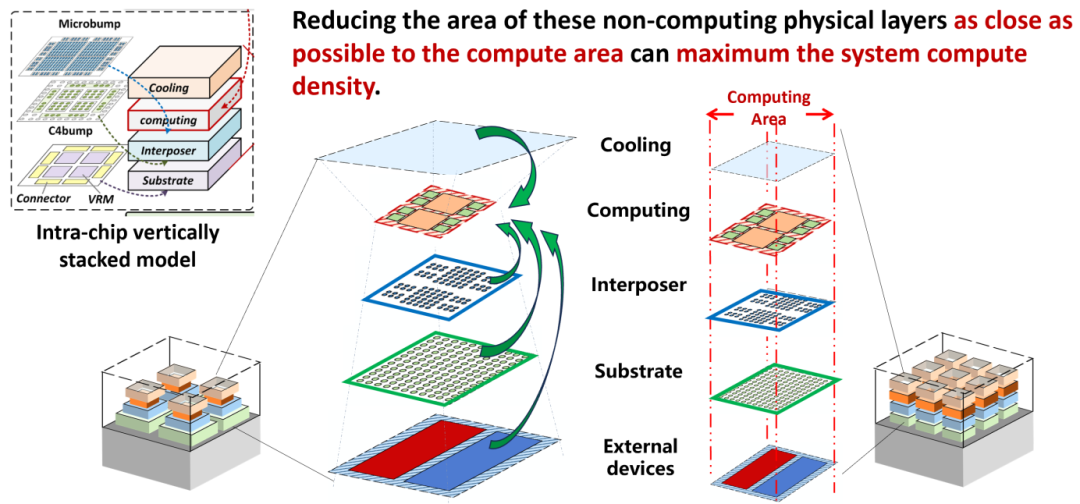
縱向面積約束跨物理層協(xié)同優(yōu)化的集成架構(gòu)設(shè)計(jì)方法
相比于一個Dojo晶圓級芯片整機(jī),采用本文提出的方法設(shè)計(jì)晶圓級芯片整機(jī)架構(gòu)能達(dá)到更高的系統(tǒng)級集成密度。在相同成本約束下,本文的設(shè)計(jì)平均提升系統(tǒng)算力2.90倍,通信帶寬2.11倍,內(nèi)存帶寬11.23倍。利用本文提出的晶圓級芯片系統(tǒng)協(xié)同設(shè)計(jì)方法,可以充分利用空間資源,大幅提高整機(jī)系統(tǒng)算力、帶寬、內(nèi)存容量等硬件性能。《WSC-LLM: Efficient LLM Service and Architecture Co-exploration for Wafer-scale Chips》提出了一種大模型推理應(yīng)用在晶圓級芯片上的編譯映射方法(第一作者為團(tuán)隊(duì)博士學(xué)生徐錚)。
本文圍繞大模型在晶圓級芯片上的推理應(yīng)用,提出了一種兼顧工作負(fù)載特性與硬件架構(gòu)特性的高效編譯映射方案。本文指出,晶圓級芯片編譯映射的核心在于充分發(fā)揮其高互連帶寬和細(xì)調(diào)度粒度的優(yōu)勢,規(guī)避尾端延遲帶來的性能瓶頸。針對大模型推理prefill和decode階段差異顯著的負(fù)載特性,本文設(shè)計(jì)了分離式映射調(diào)度方法,通過預(yù)探索策略和高效的KV cache管理策略實(shí)現(xiàn)了計(jì)算、存儲和通信資源的協(xié)同高效利用。
文中還指出,考慮到晶圓面積(約40000平方毫米)的約束,晶圓級芯片需要在計(jì)算、存儲和通信資源間進(jìn)行權(quán)衡。本文深入分析了晶圓級芯片的架構(gòu)空間,并基于靈活的硬件模版與搜索機(jī)制,探索了適配大模型推理需求的最優(yōu)架構(gòu)方案。實(shí)驗(yàn)結(jié)果表明,WSC-LLM在多種典型大模型推理任務(wù)中相較于最先進(jìn)的GPU集群方案實(shí)現(xiàn)了平均3.12倍的性能提升,展示了晶圓級芯片結(jié)合優(yōu)化編譯映射方案在未來LLM服務(wù)中的廣闊前景。本文建立了從架構(gòu)探索到編譯映射的全流程優(yōu)化方法,為大模型在晶圓級芯片上的應(yīng)用提供了關(guān)鍵支撐。
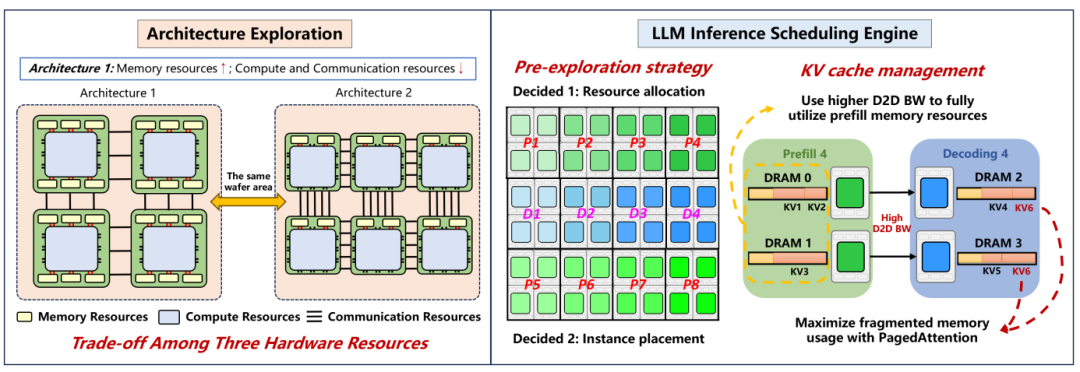
高效LLM調(diào)度與架構(gòu)協(xié)同優(yōu)化框架
行業(yè)巨頭押注,
晶圓級芯片成為AI算力未來
放眼全球,國際科技巨頭紛紛布局晶圓級芯片,目前已有兩家科技公司在該領(lǐng)域?qū)崿F(xiàn)了產(chǎn)品化突破。
全球科技巨頭特斯拉公司2021年發(fā)布了晶圓級芯片Dojo和基于Dojo構(gòu)建的AI訓(xùn)練超算系統(tǒng)?。特斯拉采用Chiplet路線,在晶圓尺寸基板上集成了 25 顆專有的 D1 芯粒。每顆D1芯粒在645平方毫米的芯片上集成了500億個晶體管, 單個Dojo擁有9PFlops算力,以及每秒36TB帶寬。
另一家晶圓級芯片公司是位于美國硅谷的AI芯片設(shè)計(jì)公司Cerebras Systems。與特斯拉的技術(shù)路線不同,Cerebras通過改變晶圓光刻流程的技術(shù)路線,實(shí)現(xiàn)光罩拼接,在計(jì)算 Die 之間插入高密度連接線,使Die 與 Die 互連形成整個晶圓級芯片。其最新晶圓級芯片產(chǎn)品WSE-3采用5nm制程,集成4萬億晶體管,性能指標(biāo)極大超越了傳統(tǒng)GPU芯片,如英偉達(dá)H100——片上內(nèi)存容量是其 880 倍、訪存帶寬是其 7000 倍、算力單元數(shù)量是其 52 倍、片上互連帶寬更是其 3715 倍。
全球半導(dǎo)體制造巨頭臺積電也在積極推進(jìn)晶圓級系統(tǒng)(SoW,System-on-Wafer)的戰(zhàn)略布局。SoW技術(shù)是指以完整的12英寸硅晶圓作為“底座”,將多個核心芯片和內(nèi)存芯片緊密連接在一起,把AI加速器、高帶寬內(nèi)存(HBM)以及輸入輸出單元(IO)等關(guān)鍵模塊,直接整合在一整塊晶圓上。通過這種方式,不僅大幅提升了計(jì)算密度和數(shù)據(jù)傳輸效率,還讓系統(tǒng)運(yùn)行更加穩(wěn)定一致。目前,這項(xiàng)技術(shù)已從研發(fā)進(jìn)入初步應(yīng)用階段,預(yù)計(jì)將在2027年實(shí)現(xiàn)量產(chǎn),進(jìn)一步鞏固了臺積電在先進(jìn)封裝和異構(gòu)集成領(lǐng)域的全球領(lǐng)先地位。
近年來,AI算力芯片作為人工智能發(fā)展的基礎(chǔ)和核心,成為大國角逐的關(guān)鍵。清華大學(xué)集成電路學(xué)院尹首一教授領(lǐng)導(dǎo)的科研團(tuán)隊(duì),深耕前沿領(lǐng)域,不斷突破技術(shù)難題,在算力芯片領(lǐng)域持續(xù)創(chuàng)新,為算力芯片的高階國產(chǎn)替代發(fā)展筑牢根基,為打破技術(shù)壁壘、實(shí)現(xiàn)自主可控貢獻(xiàn)了磅礴力量!