在科技界的平靜夜晚,OpenAI突然投擲了一枚震撼彈,將全球的目光聚焦于北京時間7月18日凌晨的一場簡短直播發(fā)布會。沒有繁瑣的預(yù)熱,也沒有璀璨的舞臺,僅憑Sam Altman和他的團(tuán)隊25分鐘的介紹,ChatGPT Agent橫空出世,成為新時代的焦點(diǎn)。
ChatGPT Agent,這位新晉的智能行動者,與我們熟悉的聊天機(jī)器人大相徑庭。它擁有自己的虛擬電腦,能夠獨(dú)立思考、規(guī)劃并執(zhí)行一系列復(fù)雜任務(wù)。在直播中,觀眾目睹了Agent熟練操控瀏覽器、解析網(wǎng)頁、調(diào)用API、制作PPT和表格的全過程,令人嘆為觀止。Sam Altman直言不諱:“看著它工作,我感受到了AGI(通用人工智能)的真實存在。”
發(fā)布會令人印象深刻之處有三:一是面對復(fù)雜多目標(biāo)任務(wù),Agent雖耗時較長,但完成度極高;二是人機(jī)協(xié)作體驗顯著,用戶可以隨時打斷Agent,補(bǔ)充信息或指導(dǎo),甚至增加新任務(wù);三是Agent通過專屬虛擬電腦執(zhí)行任務(wù),過程可視化,用戶可回放視頻查看每一步操作。

ChatGPT Agent的誕生,是OpenAI在智能體領(lǐng)域深耕細(xì)作的必然成果。今年早些時候,Deep Research和Operator兩大工具相繼問世,但各有短板。Deep Research擅長長文閱讀,卻難以應(yīng)對需要登錄和交互的網(wǎng)頁;Operator則擅長處理交互式和可視化網(wǎng)頁,卻在深度分析和長文閱讀上力不從心。而復(fù)雜任務(wù)往往需要兩者的結(jié)合。Sam Altman在發(fā)布會上道出了人們的心聲:“我們渴望一個統(tǒng)一的智能體,能自主運(yùn)行,使用專屬電腦,完成復(fù)雜任務(wù)。它能無縫切換,從思考到行動,使用各種工具,如終端、網(wǎng)頁操作,甚至生成文件。”
ChatGPT Agent正是Deep Research和Operator強(qiáng)強(qiáng)聯(lián)合的產(chǎn)物,它兼具分析與執(zhí)行能力,仿佛擁有了“大腦”和“雙手”。在發(fā)布會上,Agent展示了一個多目標(biāo)任務(wù)的執(zhí)行過程:用戶為參加朋友婚禮,需要準(zhǔn)備服裝、禮物和預(yù)訂酒店。Agent確認(rèn)需求后,耗時20分鐘,提供了詳盡的方案,包括五件服裝選項及購買鏈接。當(dāng)用戶新增參觀美國職業(yè)棒球聯(lián)盟所有球場的旅行計劃時,Agent迅速生成了精確的Excel行程表。
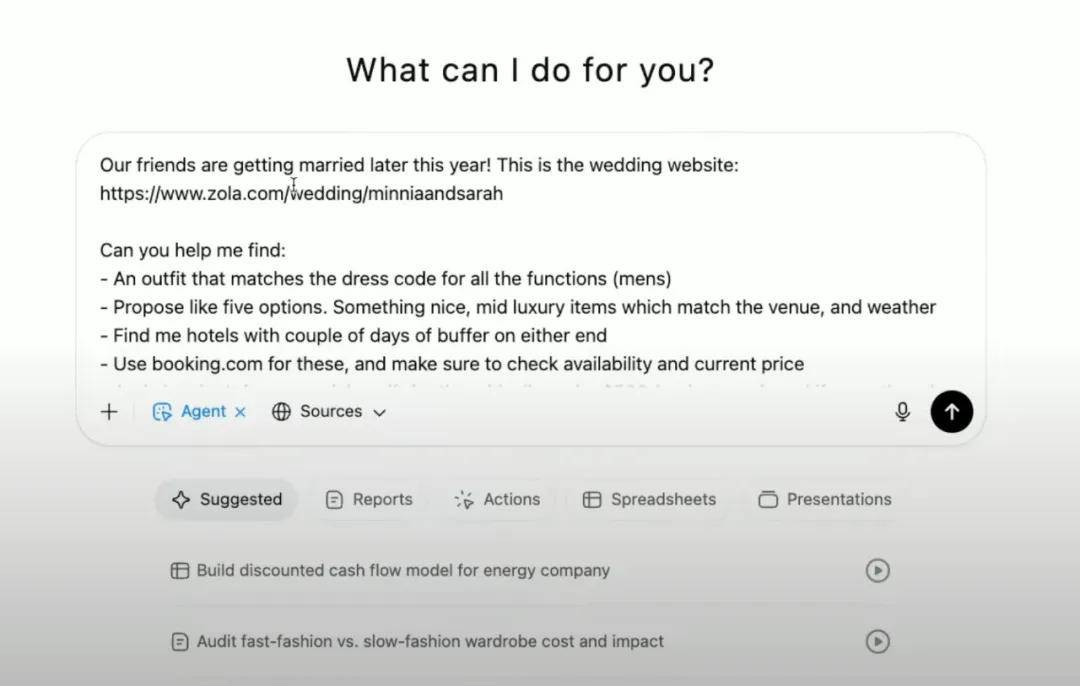
Agent的強(qiáng)大,源于其專屬的虛擬電腦和工作臺。工作臺上集成了文本瀏覽器、可視化瀏覽器、終端和API等工具。文本瀏覽器如同Agent的“大腦”,快速抓取和解析網(wǎng)頁文本,高效處理信息。可視化瀏覽器則是Agent的“眼睛”和“手”,讓它能像人一樣瀏覽和操作網(wǎng)頁。終端和API讓Agent能夠運(yùn)行代碼、進(jìn)行數(shù)據(jù)分析、處理文件,甚至生成PowerPoint和Excel文件。在發(fā)布會上,Agent自行編寫代碼編譯幻燈片,并調(diào)用圖像API美化頁面的場景,給觀眾留下了深刻印象。
OpenAI通過強(qiáng)化學(xué)習(xí)訓(xùn)練Agent,使其在面對復(fù)雜任務(wù)時,能自主規(guī)劃并智能選擇最優(yōu)工具組合。例如,在預(yù)訂餐廳時,Agent會先用文本瀏覽器篩選,再用可視化瀏覽器查看菜品圖片,最后確認(rèn)空位并完成預(yù)訂。這種高度自主和智能的選擇能力,是Agent區(qū)別于其他AI工具的關(guān)鍵。
ChatGPT Agent不僅在硬實力上表現(xiàn)出色,其高度協(xié)作的交互模式更是軟實力所在。過去,我們與AI的交互是僵硬的,只能等待任務(wù)完成。而ChatGPT Agent被設(shè)計成一個真正的“協(xié)作伙伴”,用戶和智能體可以隨時主動溝通。在Agent執(zhí)行任務(wù)的任何時刻,用戶都可以插話,補(bǔ)充要求、糾正方向或改變?nèi)蝿?wù)。Agent會理解新的指令,并在不丟失已有進(jìn)度的前提下繼續(xù)工作。同時,Agent也會主動溝通,提出澄清性問題或?qū)で笥脩舸_認(rèn),確保任務(wù)始終在掌控之中。用戶還擁有最終的“接管權(quán)”,可以隨時暫停Agent的操作,直接進(jìn)入虛擬環(huán)境修改,增強(qiáng)了用戶的安全感和控制感。
為了證明ChatGPT Agent的實力,OpenAI公布了一系列基準(zhǔn)測試成績。在HLE基準(zhǔn)測試中,Agent取得了41.6%的分?jǐn)?shù),幾乎是此前模型的兩倍。在前沿數(shù)學(xué)基準(zhǔn)FrontierMath上,Agent在工具輔助下達(dá)到了27.4%的準(zhǔn)確率。在BrowseComp和WebArena測試中,Agent同樣表現(xiàn)優(yōu)異。在SpreadsheetBench測試中,Agent的得分高達(dá)45.5%。這些數(shù)字背后,反映出ChatGPT Agent在通用推理、專業(yè)知識、工具使用和任務(wù)執(zhí)行等多個維度上,已達(dá)到全新高度。
盡管ChatGPT Agent展現(xiàn)出強(qiáng)大能力,但Sam Altman也坦誠地強(qiáng)調(diào)了其“前沿和實驗性”,并揭示了潛在風(fēng)險。最大的擔(dān)憂之一是“提示詞注入”攻擊,當(dāng)Agent訪問惡意網(wǎng)站時,可能會執(zhí)行不當(dāng)操作。OpenAI已構(gòu)建多層防御體系,但仍無法阻止所有攻擊。隨著AI能力的增長,如何劃定安全的倫理和技術(shù)邊界,已成為行業(yè)共同挑戰(zhàn)。因此,OpenAI建議用戶充分意識到風(fēng)險,不隨意透露個人敏感信息。